BlackRock’s $40 Billion Investment on Compute Power Shapes Data Center Map 6:37 AM (24 minutes ago)
In a move that influences the economics of artificial intelligence, a heavyweight consortium led by BlackRock agreed to acquire Aligned Data Centers for roughly $40 billion. Backed by Microsoft, NVIDIA, Abu Dhabi’s MGX, Elon Musk’s xAI and other investors, the deal ranks among the largest transactions in the data center sector.
Aligned, founded in 2013, operates a sprawling footprint: more than 50 campuses and over 5 gigawatts of operating and planned capacity. The buyer group, organized through BlackRock’s Global Infrastructure Partners and the AI Infrastructure Partnership, says it expects to close in the first half of 2026 pending approvals, including a likely review by CFIUS (Committee on Foreign Investment in the United States).
A Tight Market
Enormous demand for data center compute has driven this deal. Vacancy in North American data center hubs has slipped to historic lows (Northern Virginia fell below 1%), and roughly three-quarters of capacity under construction is reportedly pre-leased, mostly by cloud and AI providers, years before launch. That pre-emptive contracting creates a two-tier market: hyperscalers reserve future megawatts while enterprises scramble for the remainder.
The price backdrop reflects this scarcity. Colocation rates climbed to about $217 per kilowatt per month globally in early 2025, with major markets up high teens year over year. Private equity has been a major consolidator, accounting for the vast majority of data center M&A since 2022 as transaction values surged from $26 billion in 2023 to more than $70 billion in 2024. Concentrated ownership is expected to translate to pricing leverage.
Aligned is designed for the workloads supporting the rapid AI buildout cycle. Densities that once hovered around 40 kW per rack are moving past 100 kW and pointing to 250 kW as GPU clusters swell. The company’s modular designs, power roadmaps and patented cooling have made it a favored builder for rapid, high-density deployments. And with Microsoft and NVIDIA in the buyer mix, some of the investors are also end users.
The Aligned purchase also redefines what “infrastructure” means in the AI era. Investors increasingly view AI-ready campuses as utility-like assets: long-dated, contracted cash flows with upside from density upgrades (liquid cooling, optical interconnects) and multi-gigawatt expansion. Morgan Stanley pegs 2025 AI infrastructure spend at the high hundreds of billions. Supporting that analysis, OpenAI, Meta and others are investing aggressively to secure chips and megawatts at levels that have never been seen before. Against that backdrop, owning compute facilities becomes a strategic hedge.
New Challenges for AI Buyers
For enterprise managers, the news offers challenges. Data center capacity is increasingly allocated by long-term planning, not spot-market bids. Planning horizons stretch to three to five years. Analysts urge enterprise executives to expand beyond Tier-1 metros into secondary markets, negotiate rights of first offer/refusal on future build phases, and lock in SLAs tied to launch milestones.
Power has become the limiting factor, so strategies that secure substations, on-site generation, or preferential interconnects matter as much as square footage. There’s also now a greater reward for in-house compute planning: optimizing under-architected workloads can free meaningful compute capacity and delay expensive migrations.
For enterprise executives who need to support their AI deployments, the counter-strategy relies on major foresight and flexibility. The BlackRock deal means that it’s more important than ever to secure options early, diversify vendors and markets, and treat power supply like the first dependency in any AI roadmap.
Bottom line: the world’s AI software increasingly now runs on long-dated, less accessible contracts for data centers. If executives were on the fence about investing in AI, there’s no more time for hesitation—the available facilities are becoming far too scarce.
The post BlackRock’s $40 Billion Investment on Compute Power Shapes Data Center Map appeared first on Techstrong IT.









Global AWS Outage Traced to DNS Resolution Issue in a Single Region 4:34 AM (2 hours ago)
A global outage of cloud services provided by Amazon Web Services (AWS) disrupted access to hundreds of thousands of Web sites and applications today that were dependent as many as 78 impacted services.
AWS confirmed that there were significant error rates for application programming interface (API) requests made to the DynamoDB database endpoint in its US-EAST-1 Region. The root cause appears to be related to a Domain Name Server (DNS) resolution issue involving the DynamoDB API endpoint, according to AWS.
At 6:35am EST today, AWS reported that the underlying DNS issue has been fully mitigated, and most AWS Service operations are succeeding normally now. However, some requests may be throttled while we work toward full resolution. Additionally, some services, such as CloudTrail and Lambda, are continuing to work through a backlog of events. While most operations are recovered, requests to launch new EC2 instances or services that launch EC2 instances such as ECS in the US-EAST-1 Region are still experiencing increased error rates, according to AWS
Organizations impacted by the outage include Amazon, AT&T, Canva, Delta Air Lines, Disney+ +, Fortnite, Hulu, McDonald’s, Pokémon, Roblox, Snapchat and United Airlines.
It’s too early to assess the economic impact of this latest outage but many IT teams will undoubtedly be reviewing their dependency on cloud service providers in its wake. Additionally, calls to revamp how DNS is designed might also gain additional traction given how vulnerable the system used to provide access to Web services has proven to be of late.
JP Morgenthal, founder and fractional CTO for NexAgent Solutions, a systems integrator, said regardless of the root cause the lesson here is that distributed applications require redundancy of services to ensure high-availability. DNS-based outagesm in particular, can be extremely difficult for cloud customers because it also manages the communications within the cloud as well as external to cloud, he added.
In theory, applications running on cloud services should be able to take advantage of multiple regions to ensure availability, but given the number of recent outages involving AWS, Google, IBM, Microsoft and others, it’s clear there are multiple single points of failure. Most organizations today rely on multiple cloud service providers to run applications, but very few are designed to failover to another cloud service provider when there is a disruption, instead preferring to rely on the availability enabled by distributing application workloads across multiple geographic regions.
Jack Gold, principal for J.Gold Associates, said AWS is such an important backbone that when it experiences an issue, it ripples through the ecosystem and has a huge impact. When applications are hosted by one service, that means there is a single point of failure if for some reason that cloud service becomes unavailable or is corrupted in some way, he added.
It’s actually surprising that we haven’t seen more of these outages, which shows that AWS and others are pretty competent in keeping things running smoothly. But no system is perfect, as we see today, noted Gold.
However, there have been an increasing number of cloud outages that might drive more organizations to reconsider their strategy. According to ThousandEyes, a unit of Cisco, the most common causes of these issues are unintentional failure vectors that accidentally spread failures across a distributed environment, hidden functional failures, and misconfigurations that cascade through interconnected systems.
The challenge, of course, is to minimize those risks as much as possible in a way that doesn’t wind up breaking the IT budget.
The post Global AWS Outage Traced to DNS Resolution Issue in a Single Region appeared first on Techstrong IT.
The F5 Breach and the Fragility of Modern IT Infrastructure 1:05 AM (5 hours ago)
When F5 confirmed that a nation-state actor had infiltrated its internal systems and stolen parts of the BIG-IP source code and internal vulnerability data, it was easy to file it under “another day, another breach.” But that would be a mistake — a big one.
Because this isn’t just another cybersecurity story. It’s an IT infrastructure story — one that exposes the fragility at the heart of the systems we depend on to keep business, government and the internet itself running.
This breach, disclosed publicly by F5 in Security Advisory K000154696 and detailed by Tenable’s analysis, involved attackers stealing not only product source code but also information about unpatched vulnerabilities that F5 engineers were still triaging. That’s the equivalent of stealing the combination to the vault — along with a list of all the weak hinges and cracks in the door.
When the Foundation Cracks
To understand the significance, you have to appreciate where F5 sits in the digital ecosystem.
F5’s BIG-IP appliances and virtual editions handle load balancing, SSL termination, application delivery and network security for thousands of enterprises, service providers and government agencies. They are the unseen backbone behind many of the world’s most critical applications and data flows.
If you’ve ever logged into your bank account, streamed a show, or connected to a SaaS app hosted in a data center — odds are, an F5 product helped make that happen.
Now imagine the source code of those systems, plus details of unpatched vulnerabilities, sitting in the hands of a nation-state adversary. It’s not hard to see why CISA immediately issued Emergency Directive 26-01, requiring all federal agencies to inventory, patch and harden their F5 devices. When the people in charge of defending .gov networks say “drop everything and fix this,” you know it’s serious.

Beyond Cybersecurity: A Crisis of Infrastructure Trust
The F5 incident exposes a bigger truth that IT leaders have ignored for too long: We have built our infrastructure on monocultures.
The same way an agricultural monoculture can be wiped out by a single disease, an infrastructure monoculture can be crippled by a single exploit. If your enterprise routes 80% of its mission-critical traffic through one vendor’s technology, you’re not resilient — you’re fragile.
It’s easy to talk about “vendor consolidation” and “platform standardization” as efficiency plays. They save budget, reduce complexity and make training easier. But they also make your entire stack dependent on one company’s security hygiene, one code base, one supply chain and one set of internal controls.
When that vendor gets breached — and make no mistake, eventually someone always does — you inherit that risk instantly.
This isn’t theoretical. We’ve seen it before with SolarWinds, Kaseya, MOVEit and even Microsoft’s Storm-0558 compromise. Each time, we swear we’ve learned the lesson. And each time, market inertia pulls us right back to the same posture: Overreliance on the familiar.
A Wake-Up Call for CIOs and IT Leaders
Here’s the uncomfortable truth: This isn’t just a cybersecurity event; it’s an IT operations continuity issue of the highest order.
Let’s break down what CIOs, infrastructure heads and IT directors should take away from the F5 breach.
1. Redundancy Must Be Architectural, Not Just Hardware
You can buy all the redundant boxes you want, but if they all run the same code base, you haven’t achieved resilience — you’ve created replicated risk. True redundancy comes from architectural diversity: Different vendors, different stacks, even different security models where possible.
2. Patch Management is Now a Supply Chain Discipline
Too often, patching is treated as a tactical task. It’s not. It’s part of your software supply chain integrity. Enterprises should integrate patch verification into their ITSM pipelines, automate vulnerability scanning tied to SBOM data, and verify that updates are cryptographically signed and tracked end-to-end.
3. Transparency From Vendors Isn’t Optional
After SolarWinds, many vendors promised “secure development lifecycles.” Now’s the time to prove it. Infrastructure providers must be transparent about their internal security posture — not just the products they ship. That includes code repo security, build system integrity and insider threat controls.
4. Business Continuity Requires Scenario Planning
If your infrastructure team hasn’t gamed out a scenario where your primary vendor is offline, compromised, or embargoed, you’re already behind. Run tabletop exercises:
- What if F5 (or your equivalent) went down for 30 days?
- Could you reroute traffic?
- Could you switch providers, even temporarily?
The answers might be sobering — but they’re better discovered now than in the middle of a crisis.
The Human Side of the Equation
Let’s not forget that at the end of every infrastructure system are the humans who build, manage and maintain it. IT teams are stretched thin. They’re dealing with technical debt, tool sprawl, budget constraints and now — an adversary armed with insider-level knowledge of one of their core vendors.
This incident should also remind us of something fundamental: Security and IT ops are two sides of the same coin. You can’t run a secure infrastructure without operational excellence, and you can’t run a resilient infrastructure without secure foundations.
Shimmy’s Take
Let’s call this what it is: A five-alarm fire for IT infrastructure.
This breach isn’t just about stolen code — it’s about broken trust. It’s a vivid reminder that the reliability we take for granted is, in reality, built atop a fragile web of assumptions: That vendors are secure, that updates are safe, that code bases are clean, that no one’s watching from the shadows.
We’ve been lulled by the convenience of “single-vendor simplicity.” We talk about modernization, automation and AI-driven ops — but all that efficiency means nothing if your foundation can be compromised from the inside.
The lesson from F5 is simple: Resilience isn’t redundancy, it’s independence. It’s the ability to operate when your favorite platform, your trusted vendor, or your go-to product is suddenly part of the problem.
So yes, F5 will patch, rebuild and regain customer trust. But for the rest of us, the question lingers: How many other unseen dependencies are one breach away from shaking the digital world?
It’s time to find out — before someone else does it for us.
The post The F5 Breach and the Fragility of Modern IT Infrastructure appeared first on Techstrong IT.
AI Data Centers Drive Coal Comeback Amid Soaring Power Demand 17 Oct 6:06 AM (3 days ago)
In a paradoxical twist to the digital age, America’s newest technology, artificial intelligence, is breathing life into one of its oldest and dirtiest energy sources: coal.
Across the U.S., data centers are driving electricity consumption to levels unseen in decades. As utilities scramble to meet this soaring demand, coal generation has surged roughly 20% this year, according to a report from Jefferies Research. The trend, analysts say, may persist through 2027, delaying the retirement of plants once slated for closure.
Many Forces Supporting Coal
Driving coal’s rise is a combination of factors. Natural gas prices have risen, renewables face regulatory hurdles, and AI workloads consume power in unpredictable bursts that strain the power grid. The result is a grid stretched between the constant draw of AI training clusters and the spiky, high-frequency surges of AI inference.
In response, utilities in several states have reversed plans to shutter coal-fired generators, citing the need to serve fast-growing data center loads. In Omaha, the local power company scrapped its plan to stop burning coal at its North Omaha plant, warning that new data centers could otherwise face shortages.
The shift carries major environmental implications. Coal still accounts for more than half of U.S. power-sector carbon emissions, and every extra ton burned undermines climate targets. Greenpeace calls coal “the dirtiest, most polluting way of producing energy,” a characterization many scientists echo.
A 2024 Morgan Stanley report projects that data centers could emit 2.5 billion tons of greenhouse gases worldwide by 2030—triple what would have been produced without the explosive growth of AI. The U.S. Department of Energy estimates that data centers could consume up to 17% of the nation’s electricity by the end of the decade, a remarkable rise from about 4% today.
Yet Coal is Still Fading
But coal’s apparent new popularity is not so one-sided. Energy companies are increasingly repurposing decommissioned coal sites into hubs for new-generation power.
In Pennsylvania, the shuttered Homer City coal plant, known as a source of industrial pollution, is being converted into a massive AI data center complex, powered by natural gas and set to open in 2027. Developers are reusing the site’s high-capacity grid interconnections, bypassing the years-long queue for new power hookups.
This model is spreading quickly. Xcel Energy, which operates across the Midwest and Rockies, is converting coal units in Minnesota, Texas, and Colorado to natural gas, wind, and solar, all for projects built with data center clients in mind. The U.S. Department of Energy is supporting efforts to repurpose retired coal sites through financing, planning tools, and technical guidance, and has begun exploring how such sites might be converted into data centers.
Federal Policy Moves Away from Renewables
Helping promote coal is the recent shift in federal energy policy, which has tilted away from renewables. The Trump administration has frozen approvals for some wind projects and restricted new solar development, citing land-use and cost concerns.
As Interior Secretary Doug Burgum was recently quoted in The New York Times: “What’s going to save the planet is winning the A.I. arms race. We need power to do that and we need it now,” he said. “We need to worry about the humans that are on the planet today. The real existential threat right now is not one degree of climate change.”
That framing, treating AI capacity as a national security imperative, has intensified the push to secure any available generation, even from fossil fuels.
A Temporary Shift?
Some industry experts insist that coal’s renewed relevance is only temporary. As more nuclear, solar, and battery storage projects come online in the next decade, the balance could shift decisively toward cleaner energy. For now, however, the AI revolution depends partially on an aging fleet of coal-fired turbines, an ironic reminder that the intelligence of tomorrow still runs, at least in part, on the carbon of yesterday.
The post AI Data Centers Drive Coal Comeback Amid Soaring Power Demand appeared first on Techstrong IT.
CEO–CIO Divide Threatens AI Momentum, New Research Warns 16 Oct 7:11 AM (3 days ago)
A new global study underscores a growing disconnect between corporate leaders and their technology chiefs—a divide that could slow enterprise adoption of artificial intelligence.
According to a survey commissioned by cybersecurity vendor Netskope, Crucial Conversations: How to Achieve CIO–CEO Alignment in the Era of AI, nearly four in ten CIOs (39%) say they are misaligned with their CEOs on strategic decisions. Another 31% admit they aren’t confident they know what their CEO expects of them.
The result: one-third of CIOs feel disempowered to make long-term IT strategy decisions, even as organizations press forward with ambitious AI agendas.
The Expanding Role of the CIO
The study paints a complex picture of the CIO’s expanding role in 2025. Once confined to back-office technology operations, today’s CIOs are expected to act as co-strategists—shaping workforce policy and innovation frameworks. But this broader responsibility often comes without a matching level of executive support.
“CIOs are being asked to lead the AI charge while managing costs and risk,” said Mike Anderson, Chief Digital and Information Officer at Netskope. “But technical mastery isn’t enough anymore. To succeed, CIOs must navigate complex stakeholder relationships and communicate in the language of business outcomes.”
A Strategic Gap at the Top
The tension between CEOs and CIOs is particularly visible around investment priorities. Only 36% of CIOs say their organizations are investing enough to modernize IT infrastructure, while 41% believe spending needs to rise. A further 26% report difficulty convincing their CEO to fund modernization or transformation projects.
This investment lag carries consequences. Many AI initiatives rely on advanced, cloud-ready infrastructure capable of handling massive data flows. Without it, AI projects risk remaining prototypes rather than revenue drivers.
CEOs, meanwhile, are cautious of overspending and are pushing CIOs to integrate AI responsibly—focusing on measurable business value rather than chasing hype. The report suggests this dual mandate can easily lead to friction: CIOs are encouraged to innovate yet constrained by cost controls that limit experimentation.
Six Conversations That Define the Relationship
Netskope’s research identifies six “crucial conversations” that determine whether the CEO–CIO partnership fuels progress or stalls it. Each area reveals a flashpoint of differing expectations:
- Cost: CEOs often rely on their CIOs to act as reality checks, assessing whether tech investments truly deliver value.
- Risk: Executives expect CIOs to serve as trusted lieutenants who can gauge when to flag emerging threats.
- Innovation: CIOs must translate bold ideas into manageable, safe pilots that yield fast learnings without jeopardizing operations.
- People: With AI reshaping workflows, CIOs are now co-owners of workforce strategy alongside HR leaders, using automation that augments rather than replaces human capability.
- Measurement: CEOs confess difficulty evaluating the ROI of technology strategy—a challenge intensified by fast-moving AI developments.
- IT Estate: Many CEOs still see IT systems as an opaque “black box,” emphasizing the need for transparency around modernization plans.
As Louise Leavey, a CIO in the financial services sector, noted, “Trust is currency. CEOs must understand not just that we’re secure, but how security supports resilience and reputation.”
From Technologist to Strategist
The report’s data shows that 37% of CIOs now consider business strategy and stakeholder management more important to their role than technical expertise. Many have taken ownership of operational functions beyond IT, ranging from digital innovation to ethical AI governance. Yet without consistent CEO engagement, even highly capable CIOs risk being sidelined in crucial corporate decisions.
Industry veterans agree that alignment requires continual dialogue. “The more proactive and consistent the CIO and their teams are, the less ‘air gap’ exists between IT and the business,” said Paola Arbour, EVP and CIO at Tenet Healthcare.
The Stakes for AI Strategy
As organizations race to scale AI, this leadership divide has real consequences. Misalignment at the top can cause strategic drift, such as projects that lack clarity of purpose, inconsistent funding, or poor integration with core business priorities. Conversely, firms where CEOs and CIOs operate in lockstep tend to move faster, adopt AI more responsibly, and achieve clearer returns on investment.
Netskope’s report frames the moment as both a warning and an opportunity. For AI transformation to succeed, technology leadership must be seen not as a cost center, but as a cooperative effort aimed at competitive corporate strategy.
“AI is forcing companies to rethink what partnership at the top really means,” said Netskope’s Anderson. “Those that master that conversation will lead the next wave of digital growth.”
The post CEO–CIO Divide Threatens AI Momentum, New Research Warns appeared first on Techstrong IT.
Fivetran and dbt Labs Merger: Big Win for Open Standards Data Infrastructure 15 Oct 11:06 AM (4 days ago)
In a move poised to reshape enterprise data management, Fivetran and dbt Labs announced plans to merge in an all-stock deal that will form a $600 million annual revenue powerhouse dedicated to building open, AI-ready data infrastructure. The combination brings together two influential players in modern analytics—one known for seamless data movement, the other for data transformation—under a shared vision of openness and automation.
The two companies will have an extensive joint customer list that includes global brands such as Siemens, Roche, and Condé Nast.
Under the agreement, George Fraser, CEO of Fivetran, will lead the new company as chief executive, while Tristan Handy, founder and CEO of dbt Labs, will assume the role of president. “This is a refounding moment for Fivetran and the broader data ecosystem,” Fraser said. “As AI reshapes every industry, organizations need a foundation they can trust—open, interoperable, and built to scale with their ambitions.”
A Combined Force in Data Infrastructure
Fivetran’s strength lies in automated data pipelines that transport massive amounts of information from applications, databases, and SaaS platforms to cloud-based analytics systems. Its software has demonstrated import performance of over 500 GB/hour on large databases, offering organizations a consistent view of their information.
dbt Labs, in contrast, focuses on transforming that data—structuring, cleansing, and preparing it for analysis. Its open-source dbt Core has become a staple among data engineers, while dbt Fusion, the commercial version, provides advanced performance and observability features.
By merging, the companies aim to provide an end-to-end open data stack that integrates data movement, transformation, metadata management, and activation. The platform is designed to work across any compute engine, BI tool, or AI model—anchored by open standards like SQL and Apache Iceberg—to help enterprises avoid vendor lock-in.
“dbt has always stood for openness and practitioner choice,” Handy said. “By joining with Fivetran, we can accelerate our mission and deliver the infrastructure that practitioners and enterprises need in the AI era.”
Positioning for the AI Future
The timing of the merger underscores the growing demand for AI-ready data systems. As enterprises race to build generative AI applications, the challenge lies in unifying fragmented data pipelines that span multiple clouds, formats, and governance tools. The open architecture of the new entity suggests it will be well positioned to support that transformation.
Both companies have emphasized their commitment to maintaining dbt Core as open source under its existing license, ensuring continuity for the vibrant global community of developers who rely on it. This move reflects the companies’ broader goal of promoting open standards and interoperability, a stance that differentiates them in a market with plenty of proprietary AI platforms.
The New Standard for Open Data
The merger is one of a few across the data management landscape. Major players are positioning for dominance as AI adoption accelerates: Salesforce moved to acquire Informatica in May of this year, and Databricks snapped up Tabular last year.
Fivetran, last valued at $5.6 billion, and dbt Labs, valued at $4.2 billion, share prominent investors including Andreessen Horowitz. Executives say the new company will operate near cash-flow break-even and could eventually be positioned for a public listing, though no timeline has been disclosed.
With the merger, Fivetran and dbt Labs seek to establish what they call the “standard for open data infrastructure.” The unified company hopes to offer enterprises a simplified path to manage data pipelines at scale, designed to make open standards the centerpiece of AI-driven business intelligence.
The post Fivetran and dbt Labs Merger: Big Win for Open Standards Data Infrastructure appeared first on Techstrong IT.
NetApp Debuts AI-Ready Data With AFX Hardware, New Data Engine 14 Oct 12:36 PM (5 days ago)
At its Insight 2025 conference in Las Vegas, NetApp presented a strategy clearly targeted for the AI era: make enterprise data AI-ready, then keep it fast, governed, and recoverable. The company unveiled AFX, a disaggregated all-flash platform built expressly for AI pipelines, and a companion AI Data Engine that sits alongside storage to curate, guard, and synchronize data for generative and retrieval-augmented applications.
A same-day announcement with Cisco adds the networking muscle—400G Nexus switches—for the east-west traffic these workloads demand, with FlexPod AI integration on the roadmap.
Independent Scaling
AFX is NetApp’s first large-scale separation of performance and capacity within its ONTAP data management software platform. Controllers and NVMe flash shelves scale independently over 400G Ethernet, forming a single pool that can be dialed toward throughput-hungry training runs or broader, lower-intensity inference estates.
NetApp positions this as the foundation for AI factories (a term used quite a bit these days) with certification for NVIDIA DGX SuperPOD and support for RTX Pro servers using Blackwell Server Edition GPUs. For customers, the message is simpler: add controllers when you need IOPS, or add enclosures when you need terabytes.
A notable addition is the DX50 data compute node, which introduces GPU-accelerated processing directly into NetApp’s storage fabric. Instead of hosting general virtual machines, the DX50 is designed to offload data-adjacent tasks such as metadata analysis, vectorization, and policy enforcement. The result is a reduction in redundant data copies and faster synchronization between source updates and the AI systems that rely on that data.
AI Data Engine, Security, and an Alliance
The AI Data Engine bundles four key features that map to common pain points in enterprise AI. It offers a data curator, which supports real time data and manages vector stores natively on the platform. The Engine’s data guardrails enforce policy at the storage layer, marking sensitive content and automating redaction or exclusion. The data sync feature automates change detection and replication so models and RAG indexes stay current. And the metadata engine builds a live catalog across silos so teams can find and authorize the right datasets without manual wrangling.
On the security front, NetApp rebranded and expanded its ransomware suite as Ransomware Resilience, adding breach detection that looks for anomalous reads (rapid directory traversals, unusual user patterns) and pushes real-time alerts into a customer’s SIEM. Analysts note that performing both ransomware and exfiltration analytics in the storage layer remains rare, and positions NetApp as a defender as AI expands the attack surface.
Developing partnerships, the Cisco alliance formalizes the network piece enterprises have been stitching together on their own. By integrating Nexus 400G switching into AFX clusters, the vendors offer a full-stack pitch: storage tuned for AI, lossless low-latency fabrics, and centralized management through Cisco Intersight.
Efficient Support of AI
Taken together, AFX and the AI Data Engine are far more than a product refresh. They’re an ambitious bid to pull data preparation, policy, and search into the storage plane so AI teams spend less time plumbing and more time shipping features, even as security admins retain the controls they need.
For enterprises that have been slowed by complex systems, NetApp’s strategy appears direct: make storage the place where AI data is organized, guarded, and kept fresh—and wire it to the GPU floor with 400G network switches.
The post NetApp Debuts AI-Ready Data With AFX Hardware, New Data Engine appeared first on Techstrong IT.
Texas Instruments Unveils Solutions to Support Data Center Shift to 800 Volts 14 Oct 6:24 AM (6 days ago)
Responding to a data center environment challenged by AI’s energy needs, Texas Instruments has unveiled a portfolio of power-management devices designed to handle the massive power requirements of AI workloads, and to help hyperscalers make the leap from today’s 48-volt infrastructure to a future built on 800 VDC.
The announcement, showcased at this week’s Open Compute Project Summit in San Jose, is clearly a move by TI to become an enabler of scalable AI infrastructure. Working in collaboration with NVIDIA and other partners, the company is targeting a non-glamorous yet critical challenge of AI’s growth curve: how to deliver clean, efficient power from the grid to the GPU gate.
“Data centers are evolving from simple server rooms to sophisticated power infrastructure hubs,” said Chris Suchoski, TI’s data-center sector GM. “Scalable, efficient power systems are the foundation that allows AI innovation to move forward.”
A New Era of Power Density
Today’s data centers are voracious energy consumers. Looking ahead just a few years, it’s likely the average IT rack could consume more than one megawatt of power, far beyond the limits of current 12- or 48-volt designs. Higher voltages allow more efficient transmission and smaller cable sizes, but they also raise new engineering hurdles around safety, conversion ratios, and heat.
Texas Instruments’ latest reference architectures and modules aim squarely at these challenges. TI is collaborating with NVIDIA to build power management devices to support the expansion to 800 VDC power architecture. Its new 30 kW AI-server power-supply design includes a three-phase, three-level capacitor power factor correction converter, which has a power supply configurable as a single 800V output or separate output supplies. Another module integrates two inductors with trans-inductor voltage regulation, helping engineers boost density without losing thermal reliability.
Additionally, TI introduced a GaN converter module rated at 1.6 kW and more than 97% conversion efficiency. It’s a reminder that incremental gains in efficiency translate into huge savings at scale: every 1% improvement across thousands of racks can cut megawatts from a facility’s cooling load.
From 48 Volts to 800 Volts
Beyond component innovation, these new power management solutions from TI are addressing the shift to 800 V DC, which isn’t a simple swap-out—it changes the entire power delivery infrastructure. The company’s technical brief explores several architectures (three-stage, two-stage, and series-stacked) weighing trade-offs between efficiency, cost, and board space.
In a typical design, an 800-volt bus feeds an intermediate converter that steps down to 50 volts, then to 12.5 volts or 6 volts at the point of load. Each conversion adds a small loss, but higher intermediate voltages enable faster switching and smaller components, improving transient response for power-hungry AI accelerators. TI’s analysis suggests that with careful optimization, overall peak efficiency can approach 89% from input to core rail, a significant advance given the multi-kilowatt scales involved.
Collaboration with NVIDIA
TI’s partnership with NVIDIA underscores how closely semiconductor vendors and system builders now cooperate to meet AI’s power challenge. GPUs optimized for large-language-model training can draw hundreds of amps each. Coordinating the silicon that feeds them requires joint engineering across component boundaries.
With its new 800-volt solutions, Texas Instruments is working to position itself as a player in building the electrical backbone of the AI era, from the substation to the GPU socket. If successful, the company’s approach could redefine not just how much power data centers consume, but how efficiently that power is delivered.
The post Texas Instruments Unveils Solutions to Support Data Center Shift to 800 Volts appeared first on Techstrong IT.
Microsoft Shelves Caledonia Data Center After Local Backlash, Seeks New Site Nearby 13 Oct 6:33 AM (7 days ago)
Microsoft has halted plans to build a data center on 244 acres in Caledonia, Wisconsin, after a wave of community pushback that focused as much on process as on environmental impact. The company withdrew its rezoning application for the site, known as Project Nova, only weeks after acknowledging it was the developer behind the proposal.
In a statement, Microsoft said community feedback prompted the reversal and emphasized it remains committed to Southeast Wisconsin. The company will now work with officials in Caledonia and nearby Racine County to identify an alternative location that better aligns with local priorities.
The quick pivot is surprising given the project’s scale. Early design illustrations outlined three data center buildings and a 15-acre electrical substation on farmland west of the We Energies Oak Creek power plant. The Plan Commission had advanced a rezone on September 29, setting up a Village Board vote for October 14. Instead, the proposal is off the table—at least for that site.
Pushback Against Rural Development
A number of factors plagued the potential Caledonia facility. Residents and several local officials described a process that felt rushed and opaque. For months, Project Nova was advanced without naming the sponsor, leaving even some board members to learn Microsoft’s role at the same time as the public. That secrecy, coupled with sparse design specifics and a compressed timeline, hardened opposition. Yard signs sprouted along 7 Mile Road, and more than two dozen residents spoke against the plan at a September meeting.
The proposed site is rural—including working farmland—and critics warned that building industrial-scale infrastructure there would damage the ecosystem. Furthermore, Caledonia residents zeroed in on long-term lifecycle concerns: What happens if a data center becomes obsolete years from now? Zoning that locks in a single-use industrial footprint could leave the village with a difficult-to-repurpose shell.
And with only preliminary site plans available, skeptics said they were being asked to approve rezoning without the detail typically expected for large projects.
Microsoft’s Larger Strategy
To Microsoft’s credit, it listened and altered plans. Several trustees publicly praised the company for stepping back rather than forcing a contested vote. The decision also reflects the company’s larger strategy for data center development.
Microsoft is in the midst of a Wisconsin buildout that doesn’t hinge on Caledonia. Just south, in Mount Pleasant, Microsoft is close to bringing online a three-building campus spanning roughly 1.2 million square feet, with a second phase slated through 2028. Last month the company said it would invest an additional $4 billion in Wisconsin data centers, effectively doubling the Mount Pleasant footprint.
The lesson of Microsoft’s effort in Caledonia seems to be: hyperscale infrastructure is increasingly negotiated community by community. Even in regions eager for tech investment, projects rise or fall on transparency, pacing, and fit. Announcing a code-named initiative, seeking a quick rezone, and promising details later may be acceptable in industrial parks, but it’s a tougher sell on farmland abutting residential roads.
The back-and-forth of the Caledonia project demonstrates that communities aren’t rejecting data center outright. Instead, they’re demanding the same discipline applied to any major utility, including clear ownership, long-term stewardship, and a site plan that matches local values. In Caledonia, Microsoft appeared to have learned something. Wisconsin will still see the jobs and tax base that come with cloud infrastructure—just not at the originally planned location.
The post Microsoft Shelves Caledonia Data Center After Local Backlash, Seeks New Site Nearby appeared first on Techstrong IT.
Investing in Resilience—Where Data Centers Are Placing Their Bets Next 13 Oct 5:28 AM (7 days ago)
IT leaders aren’t just talking about reliability and modernization – they’re putting money behind it. In a recent survey by Futurum Research, in partnership with Nokia, organizations were asked what their top investment priorities are for improving data center reliability in the next year. The answers echo all the themes we’ve discussed: automation, resilience, and modernization. In this final post of our series, we’ll break down where enterprises are focusing their next round of improvements. Consider it a roadmap for a future-ready infrastructure: from advanced automation tools and incident response plans to ripping out legacy hardware, these are the areas getting the attention (and budget) of CIOs and data center operators.
Top Priorities: Automation, Rapid Recovery, Modernization
When asked to select their top three initiatives (see Figure 1) for the coming year, respondents delivered a clear message. The #1 planned investment (cited by 50% of respondents) is implementing AI-driven automation tools to reduce manual mistakes. Half of all surveyed organizations are prioritizing spending on things like network automation platforms, AIOps analytics, or orchestration frameworks – anything that can cut down human error and speed up operations. This aligns perfectly with the overarching theme we’ve seen: automation is viewed as the key to reliability. Enterprise IT teams are essentially saying, “We intend to buy or build smarter tools so our data center can run with fewer hiccups.”
The second-highest priority (42% of respondents) is improving incident response and recovery capabilities. While the first priority is about preventing outages, this one is about mitigating impact when incidents do happen. Companies are recognizing that despite all prevention, things can still go wrong – and what matters is how quickly you can bounce back. Investments here might include better incident management software, more robust disaster recovery (DR) plans, conducting regular drills or simulations, and refining runbooks so that IT teams can respond swiftly under pressure. Interestingly, alongside this, about 25% of organizations said they will “tighten change governance” – in other words, improve change control processes, approvals, and oversight as part of their reliability strategy. That makes sense: change management is often where incidents originate, so stricter governance can prevent some outages in the first place. Together, the focus on incident response and change governance shows an emphasis on operational resilience – both reactive and proactive.
The third major initiative (40% of respondents) is full infrastructure modernization or tech refresh. Many organizations are planning to upgrade their data center hardware and software wholesale. This could mean moving more workloads to cloud or new colocation facilities, deploying a new high-speed network fabric, or replacing aging servers and network gear with state-of-the-art equipment. The logic is simple: outdated technology can be a liability for reliability, so it’s better to modernize than to nurse along legacy systems. Recall that earlier in the survey, a quarter of respondents flagged “too much legacy tech” as a barrier to reliability. Now we see the response to that – rip out the old stuff. In fact, 27% specifically plan to replace or upgrade hardware (servers, network devices, power systems) to ensure their infrastructure is less failure-prone and supports modern features. Newer hardware often brings better redundancy, telemetry, and automation hooks that help with reliability, so this investment can pay off in both fewer outages and easier management.
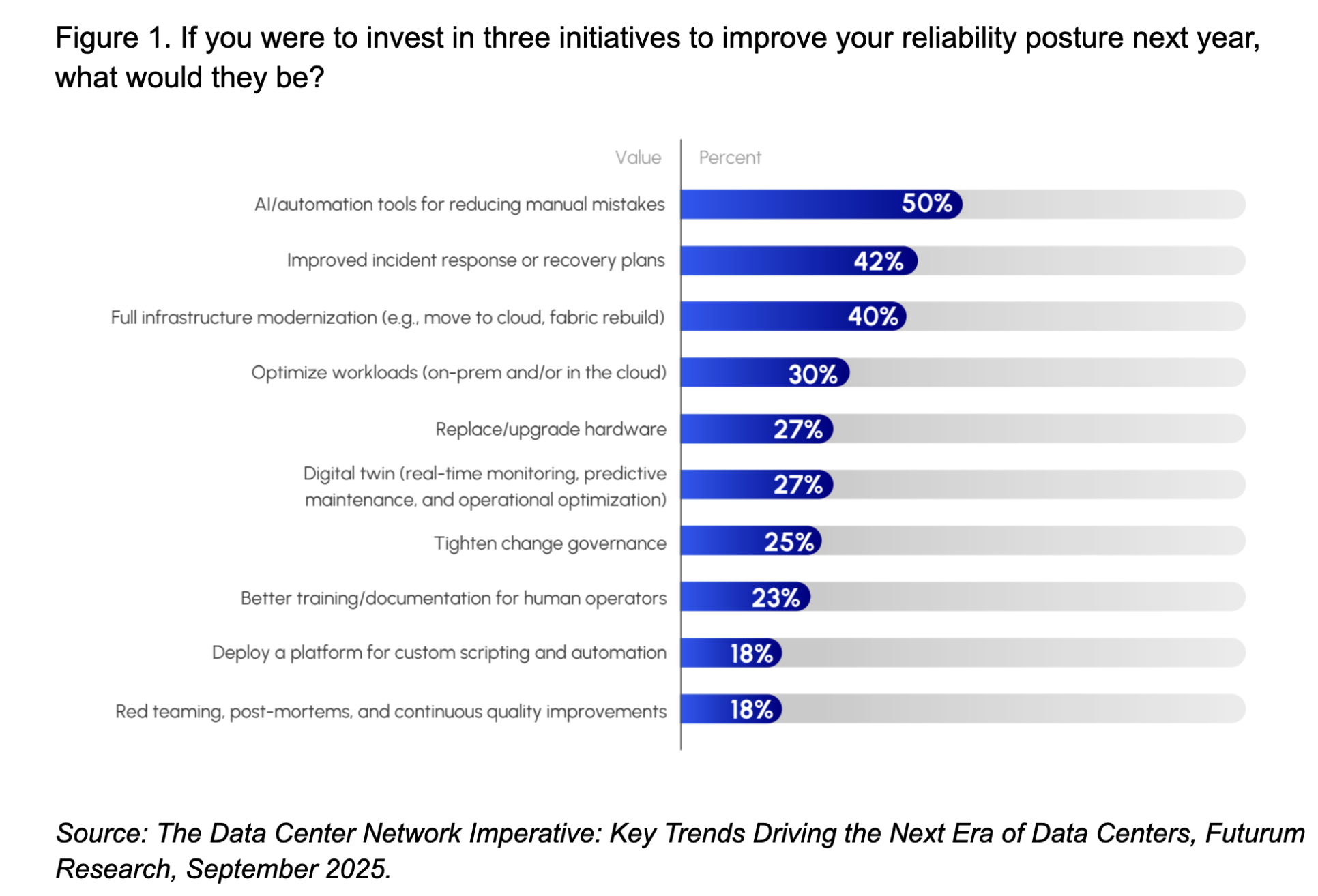
Rounding Out the Roadmap: Optimization, Digital Twins, and Training
Beyond the top three, several other initiatives are noteworthy. Optimizing workload placement across on-prem and cloud environments (selected by 30%) is a priority for about a third of organizations. This is about smart architecture – ensuring that each application or service runs in the most suitable environment for resilience and performance. It could involve shifting some workloads to cloud for better redundancy, or conversely repatriating others on-prem if that offers more control. The key is to avoid having all your eggs in one basket and to use each environment’s strengths to your advantage.
Another 27% plan to implement a network digital twin for real-time monitoring, predictive maintenance, and testing. We discussed digital twins earlier: a virtual replica of your data center network that you can experiment on safely. Investing in this indicates a desire to catch problems before they occur – by simulating changes or running “what-if” scenarios in the twin, you can prevent misconfigurations and forecast capacity issues. It’s a very forward-looking strategy to improve reliability and efficiency.

Interestingly, 23% of respondents are prioritizing better training and documentation for their human operators as a key investment area. This ties directly back to the previous post about skill gaps. Companies realize that buying fancy tools isn’t enough; you also need to upskill your team to use those tools effectively and follow best practices. Allocating budget to training programs, documentation projects, or perhaps hiring new talent shows that people remain a core part of the resilience equation. As one might say, a fool with a tool is still a fool – so training ensures your staff can leverage new tech properly (and avoid errors).
A smaller but notable slice (18%) are looking to deploy platforms for custom scripting and automation – essentially building internal tools or self-service automation platforms to address their unique needs. Another 18% cite red teaming, post-mortems, and continuous quality improvements as priorities. These may be lower percentages, but they’re the mark of more mature operations that are institutionalizing the practice of continuous improvement. Red teaming (simulating failures or attacks) and thorough post-incident reviews help organizations learn and improve over time. They complement the top priorities by ensuring that even after new systems are implemented, the organization keeps refining its resilience through practice and feedback loops.
What’s important is that even these “lower ranked” initiatives support the bigger goals. For example, doing regular post-mortems will make your incident response (the #2 priority) more effective over time. Developing a custom automation platform might feed into your broader automation push (#1 priority). The survey analysis noted that all these initiatives work in concert: modernize tech, automate ops, prepare for failures, and equip people with the right skills/processes. It’s a holistic approach to reliability.
Resilience Through Automation and Modernization
Considering all the planned investments together, a unified theme emerges: Enterprises are striving for “resilience through modernization and automation.” They’re envisioning data centers that can heal themselves and adapt on the fly – using AI to catch issues early, automation to execute changes flawlessly, and modern infrastructure to eliminate brittle, failure-prone components. At the same time, they aren’t forgetting the human element: there’s emphasis on training teams, refining processes, and planning for worst-case scenarios so that when disruptions occur, recovery is swift. In essence, the winning formula is technology plus teamwork.
From a strategic perspective, this balanced investment approach is wise. A CIO looking at these results might conclude: “We should budget for advanced automation software and schedule more incident response drills; invest in new hardware and maybe hire a network reliability engineer.” The survey data validates that both sides of the coin matter. For vendors or solution providers reading this, it’s a hint that positioning your product as part of a “resilient infrastructure toolkit” will resonate. If you can show that adopting your solution leads to tangible reliability gains – fewer outages, faster recoveries, smoother migrations – you’re speaking the language that IT execs are listening for.
What’s the Major Theme?
Enterprises are putting their money where the problems are: Automation, reliability, and modernization initiatives. If you’re an IT decision-maker, take a cue from these trends. Ensure your upcoming budgets align with reliability goals – this might mean approving that AIOps pilot, allocating funds for a network refresh, or expanding your training programs. The survey suggests that those who invest smartly in these areas will pull ahead in uptime and agility. Consider kicking off a pilot project in a cutting-edge area like AI-driven operations or digital twin technology to stay ahead of the curve. These exploratory projects can yield big dividends in understanding how new tech fits into your environment.
For those on the enterprise side, also look at your current pain points: if human error is causing issues, maybe prioritize an automation tool or an employee training initiative. If legacy systems are a headache, plan that tech refresh sooner rather than later. The data center is rapidly evolving, and being proactive is key. As the survey conclusion put it, the industry is shifting from traditional manual operations to a more autonomous, resilient paradigm. Embracing that shift – by investing in both cutting-edge tools and the people who use them – is the way to build an “always-on” data center that can meet the digital business demands of tomorrow.
In summary, the future-ready data center will likely feature self-healing networks, predictive analytics preventing failures, and seamless hybrid cloud integration. Getting there requires starting now. So, take a hard look at your roadmap: are you funding the initiatives that will make your infrastructure more robust and intelligent? The leading companies are, and they expect those investments to pay off in fewer outages, greater efficiency, and more confidence in their IT backbone. The race to resilience is on – and with the right investments, your organization can cross the finish line as a winner in uptime, innovation, and customer trust.
This blog post is number 5 in a series of 5. To see the other posts, visit: https://techstrong.it/category/sponsored/nokia-blog-series/
You can also find results from the full study here.
The post Investing in Resilience—Where Data Centers Are Placing Their Bets Next appeared first on Techstrong IT.