Briefing 274: Der KI-Boom und seine physischen Grenzen 18 Oct 2:18 AM (2 days ago)

Heute wagen wir einen Makro-Blick auf KI, das große Nachfrage sieht, sich aber immer deutlicher einigen Nadelöhren außerhalb der eigentlichen Technologie gegenüber sieht, die am Ende vielleicht zu eng sind für die Erwartungen an die Technologie.
Besonders der China-Aspekt unten könnte sehr wichtig werden. Wie wir bereits neulich im Briefing besprochen hatten: Man kann wichtige Wirtschaftszweige wie KI heute nicht mehr ohne Geopolitik denken.
Nächste Woche wird es kein Briefing geben. Das nächste Briefing erscheint übernächste Woche.
Marcel
Im Fokus der Ausgabe:
OpenAIs Billionen-Wette stößt an physische Grenzen: Das explosive Wachstum von KI trifft auf reale Nadelöhre wie Energiebedarf und Infrastruktur.
China nutzt den Hebel der seltenen Erden: Peking setzt seine Dominanz bei kritischen Rohstoffen als Waffe im Wirtschaftskrieg ein, um auch die westliche Chip-Produktion und den KI-Sektor zu treffen. (und über Bande damit die gesamte US-Wirtschaft)
Deutschlands KI-Infrastruktur fällt zurück: Ein neuer Report zeigt, dass Deutschland bei der KI-Rechenkapazität international den Anschluss zu verlieren droht.
Neue Player, neue Märkte: Während in den USA Robotik-Startups durchstarten, drängen chinesische Tech-Firmen mit selbstfahrenden Autos aggressiv auf den europäischen Markt.
Außerdem: Walmart bei ChatGPT, Social bei Sora, mehr Unternehmen bauen humanoide Roboter und mehr
Zitat des Tages
the choice isnt between "code written by ai" and "artisan handwritten code written by john carmack"
the choice is between "code written by ai" and "something that could have existed, but didnt"
Thema der Woche
Blasen, Wetten, Grenzen & Kapazitäten: OpenAIs Fünfjahres-Geschäftsplan, um die Ausgabenversprechen in Höhe von 1 Billion Dollar zu erfüllen
Parallel zum Best-Case-Szenario für OpenAI, über das wir hier letzte Woche gesprochen haben, hat die Financial Times über die Pläne und den Stand bei OpenAI geschrieben.
Die Fakten:
- OpenAI plant neue Einnahmequellen und Finanzierungsmodelle, um über $1 Bio. an Verpflichtungen zu stemmen.
- Ziel: maßgeschneiderte Produkte für Firmen und Regierungen, Shopping-Tools, Video-Service Sora, AI‑Agenten und Hardware.
- Verpflichtung: >26 GW Kapazität von Oracle, Nvidia, AMD, Broadcom mit Kosten über $1 Bio. in 10 Jahren. (Analysten: 20 GW entspricht ~20 Atomreaktoren an Strombedarf.)
- Aktuell ~$13 Mrd. ARR, 800 Mio. Nutzer, 5% zahlend; OpenAI will Zahl der Abonnenten verdoppeln.
- Hohes Defizit: H1‑Betriebsverlust ~ $8 Mrd.; Infrastruktur bislang von Partnern vorfinanziert; OpenAI setzt auf fallende Kosten und weitere Kapitalrunden.
Anmerkungen:
Zuerst: ChatGPT wird erst Ende November drei Jahre alt und liegt bereits bei 13 Milliarden $ jährliche wiederkehrende Einnahmen. Zum Vergleich: Zalando, das einzige Startup der letzten 2 Jahrzehnte, das zu einem deutschen, börsennotierten Konzern herangewachsen ist, hat für 2025 die Prognose herausgegeben, auf einen Umsatz von 12,1 bis 12,4 Milliarden Euro zu kommen. (Handelsbatt) Das erreichen sie im 17. Jahr ihres Bestehens.
Gleichzeitig wachsen OpenAI und Anthropic (und sicher auch andere wie Together.ai) rasant weiter und haben „nur“ ein Kapazitätsproblem, kein Nachfrageproblem.
Reuters reports that the company is on track to hit $9 billion in annualized revenue this year and projects as much as$26 billion annualized revenue next year. (It was at $1 billion in ARR in January.)
1 Milliarde $ ARR letztes Jahr, dieses Jahr 9 Milliarden $ und nächstes Jahr 26 Milliarden $ ARR. Dauert nicht mehr lang, und wir reden hier über ein richtiges Geschäft.
Neben dem irrsinnigen Umsatzwachstum ist auch die schiere Nutzungsgröße etwas, das vielen in den breiteren Debatten gar nicht deutlich zu sein scheint. Noch vor dem dritten Geburtstag hat ChatGPT 800 Millionen wöchentlich aktive Nutzer:innen erreicht. Facebook hat ein Vielfaches dieser Zeit gebraucht. Preisfrage: Wer gehört zu den größten Werbeplattformen der Welt? Richtig, Meta mit Facebook und Insta. Follow-Up-Frage: Könnte ChatGPT neben dem Abo-Modell zusätzlich ein vergleichbar florierendes Werbemodell etablieren? Follow-Up-Frage: Wo hören die Einnahmequellen auf, wenn man Leute dazu bewegen kann, für ein Abo zu zahlen, Nutzungszahlen und -art wie Facebook und Google aufbaut (Werbung), eigene Gadgets baut (Apple) und mit E-Commerce-Integration auch auf Konfrontationskurs mit Amazon geht (Gebühren von Händlern)? Follow-Up-Frage: Gonna be a man, ask her out?
Vor diesem Hintergrund muss man die massiven Investitionen sehen. Diese Investitionen und Vereinbarungen, eingefädelt vom Deal-King Altman, sind natürlich per Definition Wetten. Weil niemand weiß, wo die Reise hingehen wird. Aber aktuell sieht es aufgrund der auf sie von allen Seiten einprasselnden Nachfrage noch nach geringem Risiko aus.
Geringes Risiko, wenn man nur auf die Nachfrage schaut, die nur von Rechenkapazität, Chipeffizienz und Energiekosten beschränkt wird.
Anders sieht es aus, wenn man auf eben diese Schranken schaut.
Greg Brockman, the company’s president, last week said recent spending commitments would pay for themselves: “If we had 10 [times] more compute [computing power], I don’t know if we’d have 10 [times] more revenue, but I don’t think we would be that far.”
Es dürfte kaum noch einen erwachsenen Menschen im Westen geben, der/die nicht weiß, was ChatGPT ist. Diese enorme Markenwahrnehmung geht einher mit der enormen Nützlichkeit der Technologie. Für Anthropic und Co. arbeitet auch letzteres, aber ihnen fehlt ersteres (die populäre Marke).
Aber kommen wir zu den Grenzen:
These ambitious plans will need to become reality if OpenAI is to meet its liabilities, as the group has made funding commitments that dwarf its income. In the past month, chief executive Sam Altman has committed to take more than 26 gigawatts of capacity from Oracle, Nvidia, AMD and Broadcom, at a rough cost of well over $1tn over the next decade, according to FT calculations. [...]
The company’s deals with AMD and Nvidia are staggered so OpenAI will pay as new capacity is developed. But 20GW of capacity would require power roughly equivalent to that provided by 20 nuclear reactors, and analysts have questioned whether it is realistic for that demand to be met by a single company.
Wo soll's herkommen? Vor allem kurzfristig? Innerhalb der nächsten 3 Jahre? Selbst wenn kleinere modulare Atomkraftwerke regulatorisch einfacher genemigt und damit zu bauen werden, wird Energiezubau länger dauern. Wer hält es für realistisch, dass im gesamten Westen in den nächsten 10 Jahren pro Jahr 2 neue Kernkraftwerke gebaut werden?
Das heißt: Die Obergrenze für KI-Nutzung liegt neben der steigenden Effizienz der High-Tech-Chips (die Energiebedarf senken kann) auch beim Zubau von Energie. Neben, wie wir hier bereits mehrfach diskutiert haben, den organisatorischen Herausforderungen. (Prozessveränderungen sind systemische Herausforderungen, die internen Widerstand überwinden müssen.)
Und: Ein nicht geringer Teil der künftigen Infrastruktur wird außerhalb des Westens liegen. (Ein Effekt zweiter Ordnung könnte sein, dass nicht nur das Training sondern auch die Inferenz, also die Nutzung, von KI außerhalb des Westens in Ländern wie China günstiger sein wird. Zusätzlich zu allem, was man so mit Strom anstellen kann.)
Länder wie China oder Bhutan werden globale Gewinner aufgrund ihrer Energiestrategie. China baut im Jahr zweimal so viel Solarkapazität auf, wie die USA insgesamt bis heute gebaut haben. Oder auch: zwei Mal so viel wie der Rest der Welt zusammen im selben Zeitraum:
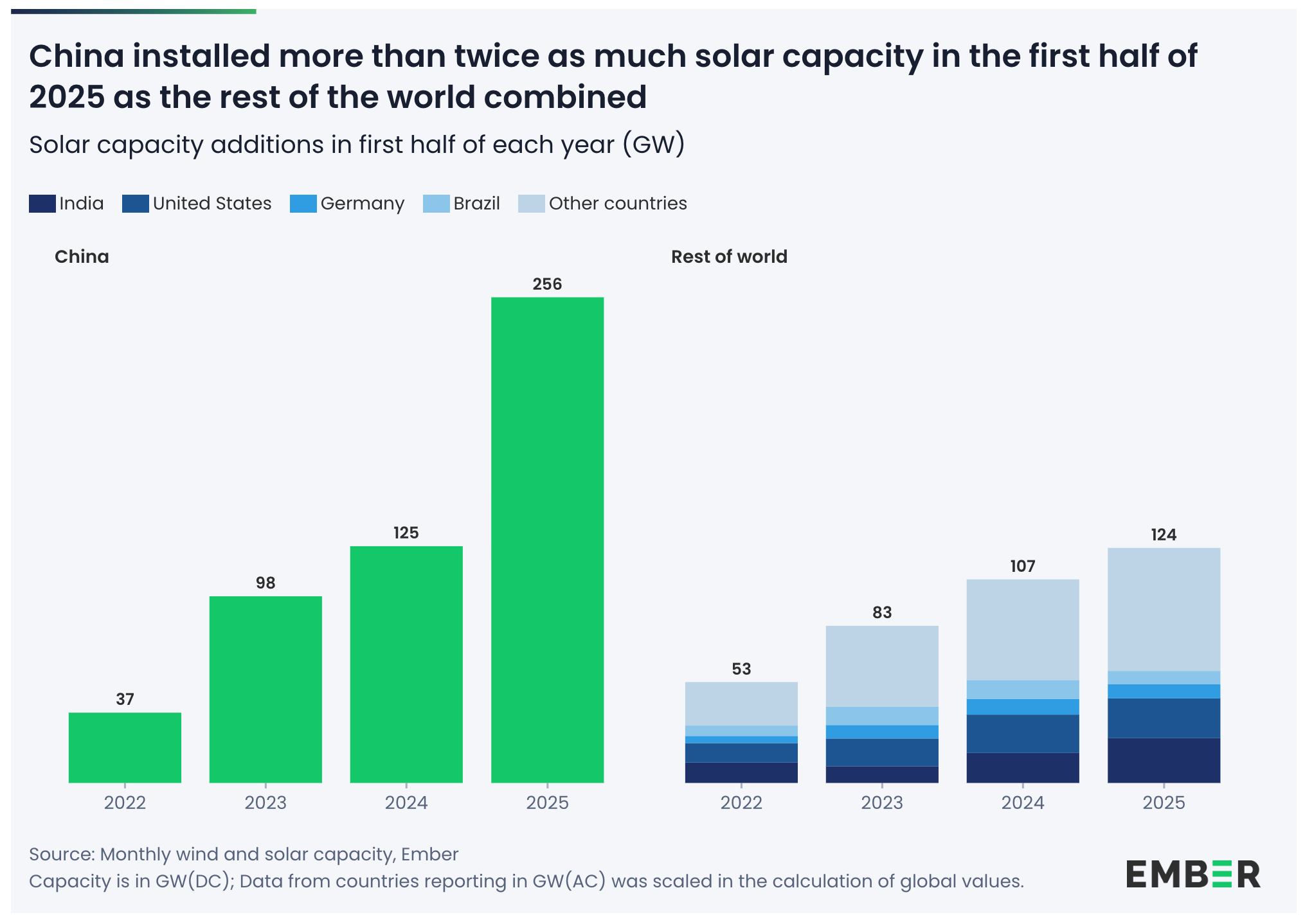
China bereitet außerdem vor, den nächsten größten Staudamm der Welt in Betrieb zu nehmen. Der Drei-Schluchten-Damm in China kommt allein bereits auf 22,5 GW. Das nächste Staudamm-Projekt in China soll sogar auf 300 TWh Strom pro Jahr kommen. Bhutan ist ein kleines Land nördlich von Indien, das dank seiner geografischen Lage ebenfalls günstige Wasserkraftwerke bauen kann und explizit für KI aufbauen will. (Economist)
Deshalb rede ich seit langem davon, dass wir insgesamt von KI-Infrastruktur reden müssen, was nicht nur KI-Modelle, sondern eben auch Chips und Strom einschließt. Dieser Text von mir dazu in der FAZ ist bereits ein Jahr alt:
Wer steigende Nutzung und wachsende Ansprüche für das Training neuer KI-Modelle extrapoliert, entdeckt schnell mehr und mehr Engstellen. Heute sind die knappen KI-Chips der bedeutendste Flaschenhals. Der nächste ist der wachsende Strombedarf. Wenn KI wirklich transformativ für die gesamte Wirtschaft ist, dann müssen wir die Anforderungen an ihre Infrastruktur sehr viel ernster nehmen.
Passiert ist dazu in Europa in diesem Jahr nichts Nennenswertes.
But wait, there is more. OpenAI und Nvidia wollen beide auf die jeweils eigene Art (und teils gemeinsam) mit ihren zirkulären Deals parallele Investitionen anschieben, um vom gesamten Ökosystem möglichst viele Beschränkungen zu entfernen:
Two-thirds of the cost of developing new computing power goes towards semiconductors. OpenAI is aiming to stimulate the nascent chip financing market by offering enormous demand, and by forging novel contracts, such as its Nvidia and AMD deals.
Für Nvidia ist das sinnvoll: Was hat Nvidia davon, wenn sie liquides Kapital auf die hohe Kante legen, während ihre Abnehmer und deren Kunden langsamer wachsen, als es möglich wäre? Für OpenAI ist das auch sinnvoll: OpenAI schafft Nachfrage im Ökosystem (etwa für spezifische KI-Chips), so dass die Komponenten schneller für sie verfügbar werden und das gesamte Umfeld grundsätzlich mehr von ihren Produkten konsumieren kann.
Gleichzeitig merkte Ben Thompson diese Woche in seinem Sharptech-Podcast einen wichtigen Aspekt an. Indem OpenAI große Deals mit Nvidia, AMD, Oracle, Softbank und Co. eingeht, binden sie diese Unternehmen auch an das Schicksal von OpenAI. Das verschafft OpenAI langfristig zumindest ein Sicherheitspölsterchen, wenn’s an anderer Stelle mal knapp wird mit dem Kapital. (Da blinzelt er uns wieder an, der kleine Machiavelli namens Sam.)
Die Sinnhaftigkeit bei beiden Unternehmen ändert aber nichts daran, dass zirkuläre Deals (ich investiere in dich, damit du unter anderem mehr von meinen Produkten kaufen kannst) ein Symptom von Spekulationsblasen sind. Ein anderes Symptom sind Investitionen, die über Kredit finanziert werden. Die ersten drei Jahre des KI-Booms wurden finanziert von VC und vom Cashflow der Tech-Riesen. Jetzt gehen wir zur Krediten über. Namentlich vor allem bei Oracle.
Aber worauf ich eigentlich hinaus wollte: Seltene Erden.
Seltene Erden: Der Wirtschaftskrieg erreicht KI









Briefing 273: ChatGPT = Apple-Appstore + Google-Suche + WeChat-Superapp 10 Oct 7:52 AM (10 days ago)

Ich werde die Tage noch etwas über Sora und Vibes schreiben, möchte aber bereits diese neue Bezeichnung in die Runde werfen: User Prompted Content.
Marcel
Im Fokus dieser Ausgabe:
- ChatGPT: Das neue Monster
- Figure 03 und die Skaleneffekte für humanoide Robotik
- KI-Browser Dia und Comet frei verfügbar; eine kurze Einordnung der KI-Implementierung von Perplexity (it's not good)
- Das Ende der Hashtags
- und mehr
Zitat des Tages
I am hearing similar things in economics & the social sciences. Not autonomous work, but expert-directed AI is absolutely helping academics do novel research in significant ways. Especially Pro/High Thinking models.
Ethan Mollick in Reaktion auf Kevin Weil von OpenAI auf X:
✨ GPT-5 crossed a major threshold: over the last two months, we’ve heard repeated examples of scientists successfully directing GPT-5 to do novel research in math, physics, biology, CS, and more. If you have an example to share, please reply below! Prizes for the best ones 🧵👇
Als Beispiel siehe etwa Mathematik-Professor Terence Tao auf Mastodon.
Ich habe auch schon einige öffentliche Aussagen dieser Art gesehen, in der Regel in Bezug auf GPT-5 Pro, das bis diese Woche dem 200$-Plan vorenthalten war.
GPT-5 Pro ist jetzt via API verfügbar.
Thema der Woche: OpenAI DevDay
Im Grunde steht bereits alles in der heutigen Überschrift.
Nach GPTs und Plugins kommt jetzt die echte ChatGPT-Plattform. GPTs sind notwendig, aber zu wenig, Plugins sind gescheitert. (Ich glaube, ich habe seinerzeit gar nicht über Plugins geschrieben, mit der Ahnung, dass es nicht weit gehen wird.)
Aber jetzt werden Dienste direkt im Chat nutzbar.
In‑Chat‑Erlebnisse: Nutzer:innen können Apps per Name aufrufen und eingebettete, interaktive Inhalte sehen – z. B. Zillow‑Karten – ohne ChatGPT zu verlassen.
Entwickler‑Tools: OpenAI’s Apps SDK (Preview) und das Model Context Protocol ermöglichen es Apps, Daten, Werkzeuge und Workflows direkt in Chats einzubinden.
Verfügbarkeit: Die Funktion ist für Free‑, Go‑, Plus‑ und Pro‑Nutzer außerhalb der EU verfügbar. (Goddamnit)
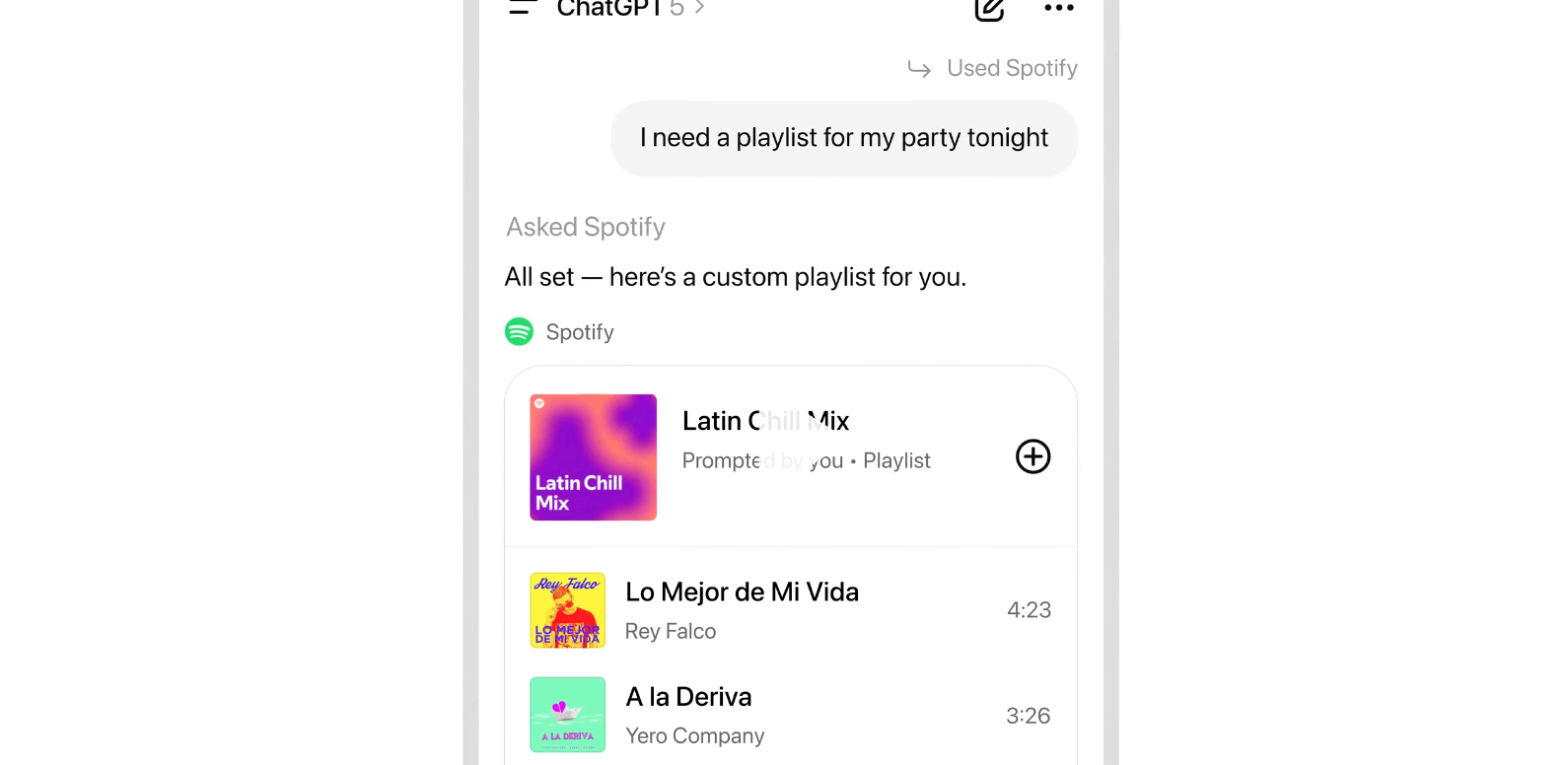
Spotify‑Details als Bsp.: Spotifys Integration bietet maßgeschneiderte Empfehlungen, Stimmungs‑/Genre‑/Artist‑Playlists und Klick‑zum‑Anhören; Inhalte der Plattform werden nicht mit OpenAI zum Training geteilt.
Weitere Apps kommen: Künftige Integrationen sind u. a. von Uber, DoorDash, Instacart und AllTrails angekündigt.
Im Stratechery-Interview spricht Sam Altman explizit darüber, dass diese Integration besser für die Partner ist, man hätte auch Dinge machen können, die für die Nutzer:innen besser gewesen wären. Das ist unser kleiner Machiavelli, wie er im von der gesamten Branche gelesenen Newsletter sagt: Wir haben eine faire Plattform für euch gebaut.
Man muss das alles vor dem Kontext der Größe von ChatGPT sehen: Mittlerweile um die 800 Millionen wöchentliche Nutzer:innen. (Das ist sehr groß, riesig sogar für einen Dienst, der noch keine drei Jahre alt ist, aber dass sie keine DAUs nennen, ist... mindestens interessant.)
Diese Integration in die Chat-Oberfläche ist der Beginn der Plattform und des neuen von OpenAI gepushten Paradigmas.
ChatGPTs Distributionsgröße zieht die App/Service-Anbieter hinein.
Es reden bereits einige vom AI-Betriebssystem. Das ist nicht weit weg. Aber die Implikationen gehen weiter, als den meisten klar sein dürfte.
ChatGPT = Apple-Appstore + Google-Suche + WeChat-Superapp
OpenAI braucht Service-Integrationen für ihre kommenden KI-Gadgets.
Die Frage, wo die Apps herkommen sollen, hatte ich für KI-Gadgets allgemein aufgeworfen.

Die größte offene Frage bei all den KI-Gadgets wie Humane AI Pin oder Rabbit R1: Du kannst die App-Rankings einer beliebigen Kategorie nicht auf die Zahl 1 eindampfen. KI ist mächtig, aber ganze Branchen wegabstrahierende Chatbots werden aus offensichtlichen Gründen nicht das nächste große Interface sein. Was also stattdessen tun?
Denn was das Eindampfen bedeutet, kann man bei Humanes AI Pin sehen. Musik beim AI Pin heißt: Tidal. Das hat nicht die Nutzerin ausgesucht. Es ist das Ergebnis eines Hinterzimmerdeals zwischen Humane und Tidal.
OpenAI löst mit der Distributionsmacht von ChatGPT am Desktop und im Smartphone die Frage, wo die Apps für die kommenden Gadgets herkommen sollen.
Das löst nicht zu hundert Prozent die Frage nach dem Long Tail der Apps, lokale ÖPNV-Apps etwa. Es löst auch (noch) nicht die Frage nach der Discovery. Aber das ist alles lösbar.
Wir sehen hier ganz klar eine Vision entstehen: Hier wird ein neuer Tech-Riese gebaut, in dessen Zentrum KI steht. Alles neu gedacht mit KI im Zentrum.
Das ist dann, völlig erwartbar, etwas Neues.
Es vereint Apples Appstore und Googles Playstore (Apps!) mit der Google-Suche (es gab mal eine Zeit, da haben Leute geschrien, KI würde nicht Google ablösen haha!) und (und!) dem Superapp-Konzept von WeChat.
ChatGPT wird Discovery von (Web-)Themen + Basis für Gadgets + die erste Superapp im Westen!
Denn all die Apps werden über kurz oder lang auch in ChatGPT in iOS und Android verfügbar sein. Allgegenwärtig.
Das bringt mich zurück zu meiner allgemeinen Arbeitsthese: Als Sascha mich im Sommer in seinem Podcast fragte, ob es am Ende gar nicht um das Gadget ginge, sondern vielmehr um den KI-Browser als Zugangsweg, war meine Antwort: jein. Weder noch. Denn:
KI ist ein Cloud-Thema.
Zumindest was den Consumerbereich angeht.
KI in der Cloud ist das Zentrum, von dem aus alle Touchpoints bedient werden. Das zu Ende gedacht vereint bisher strikt getrennte Kategorien und schafft ein komplett neues Monster.
Ob sie das erreichen werden, hängt von vielen Faktoren ab. Die Chancen stehen gut.
Es gibt im Westen nur 2 Unternehmen, die dieses Spiel überhaupt spielen können, weil sie die Distribution und die technische Expertise haben: OpenAI und Google.
Über Sora reden wir ein anderes Mal. Aber man muss festhalten: Es ist bereits der zweite Hit von OpenAI nach ChatGPT. Something to ponder.
🦾 Robotik
Figure 03: Vertikal integrierter humanoider Roboter, auf dem Weg zur Massenfertigung

Figure stellt Figure 03 vor, einen humanoiden Roboter mit neuer Hardware und Software, der für Helix, den Einsatz im privaten Haushalt und Massenfertigung entwickelt wurde.
Ich empfehle allen, sich das Werbevideo anzuschauen:
Was Figure auszeichnet, ist die vertikale Integration: Die erste Iteration wurde mit einem OpenAI-Modell betrieben. Helix, das KI-Modell hinter den Robotern, ist eine Eigenentwicklung.
Neue Sensorik und Hände für Helix: Kameras liefern 2x Bildrate, 1/4 Latenz und 60% größeres Sichtfeld; Fingertip-Sensoren erkennen Kräfte ab 3 Grammfür feinmotorische Kontrolle.
Home-Optimierungen: 9% geringere Masse, weichere Textilien, waschbare Soft-Goods, 2 kW induktives Laden in den Füßen und verbesserte Audioleistung (Lautsprecher 2x größer, ~4x Leistung).
(Soft Goods = "Kleidung" für den Roboter)
Strategisch entscheidend ist, dass Figure 03 für Massenfertigung neu konstruiert wurde: Umstellung auf Druckguss/ Spritzguss, neue Zulieferkette, BotQ-Fabrik mit anfänglicher Kapazität bis zu 12.000 Robotern pro Jahr und Ziel 100.000 in vier Jahren.
KI-gestützte Robotik wird in den nächsten 20 Jahren zum größten Markt der Welt anwachsen. Innerhalb dieses Marktes wird der humanoide Formfaktor die bestimmende Unterkategorie werden, weil sie am flexibelsten einsetzbar ist. Aus dieser Flexibilität folgen enorme Skaleneffekte dank Massenproduktion.
Das scheint, siehe unten, in Europa noch kaum jemand zu erkennen.
Zumindest das US-Unternehmen Figure ist eine sehr eindeutige Wette auf diese These.
Sie werben auch für den Einsatz im Gewerbe: Schnellere Aktuatoren (2x), bessere Greifstabilität bei variierenden Objekten, drahtloses Laden und 10 Gbps mmWave-Dataoffload für Flotten-Lernen.
• Helix: Figure 03 features a completely redesigned sensory suite and hand system which is purpose-built to enable Helix - Figure's proprietary vision-language-action AI.
• The home: Figure 03 has several new features, including soft goods, wireless charging, improved audio system for voice reasoning, and battery safety advancements that make it safer and easier to use in a home environment.
• Mass manufacturing: Figure 03 was engineered from the ground-up for high-volume manufacturing. In order to scale, we established a new supply chain and entirely new process for manufacturing humanoid robots at BotQ.
• The world at scale:The lower manufacturing cost and the advancements made for Helix have significant benefits for commercial applications. Figure 03 introduces a fully redesigned sensory suite and hand system, purpose-built to bring Helix to life.
Softbank kauft ABB Robotics aus der Schweiz
Jetzt ist der Zeitpunkt, um in Robotik-Fähigkeiten zu investieren und notfalls Robotik-Übernahmen regulatorisch sehr genau zu betrachten.
OpenAI-Investor Softbank übernimmt also ABB Robotics.
Reuters:
SoftBank pushed into humanoid robotics a decade ago with its Pepper robot but later scaled back its ambitions.
Its recent investments in the sector include Berkshire Grey and AutoStore, and it also led a $40 billion funding round in ChatGPT-maker OpenAI and in March bought chip design company Ampere for $6.5 billion.
"SoftBank's next frontier is Physical AI," Son said in a statement.
The deal means ABB has abandoned its original decision to spin off and separately list the industrial automation business, which competes with Japan's Fanuc (6954.T), opens new tab and Yaskawa (6506.T), opens new tab, as well as Germany's Kuka in making factory robots.
"Germany's Kuka" ging 2016 an den chinesischen Konzern Midea.
🤖 KI
KI-Browser Dia und Comet frei verfügbar
Nachdem das Gericht in den USA entschied, dass Google den Browser Chrome behalten und alle Unternehmen von Apple bis Mozilla weiter bezahlen darf, landet Gemini langsam aber sicher in Chrome. Vertikale Integration incoming!
In der Zwischenzeit, den Atem im Nacken spürend, sind Dia und Comet jetzt frei verfügbar.
Dia hat jüngst eine Memorysuche eingeführt:
Just type @Search Memory into any Chat or Skill to call the right context from your past week of browsing,_ right when you need it._ Ask for that Notion doc your boss sent; summarize discussions with a close collaborator across Slack, Gmail, and Notion; or even build a Skill that helps you reflect on your last week and shape the next one.
Siehe dazu auch meine Analyse vom Sommer:
https://neunetz.com/briefing-267-ki-browser-sind-der-neue-plattformkampf/
Da Perplexity für maximales Wachstum und dafür verschenkte Pro-Pläne die eingebundenen Modelle maximal verblödet*, ist Dia, das mittlerweile zu Atlassian gehört, mein aktueller Kandidat für den vielversprechendsten KI-Browser.
*Es gibt Unterschiede wie Tag und Nacht bei Inferenzanbietern und noch stärker bei Startups, die gegen einen festen Jahres-/Monatsbetrag Zugang zu Modellen anbieten. Letztere können etwa das Kontextfenster gering halten, um möglichst wenige Input-Token zu bezahlen. Das merkt man bei Perplexity etwa daran, dass Follow-Up-Fragen oft ins Leere führen. Es gibt noch andere Hebel, die Kosten und Qualität senken können.
Planbare Lücke zwischen LLMs und SLMs
Das ist sehr wichtig. Frontier AI Performance Becomes Accessible on Consumer Hardware Within 9 Months:
Using a single top-of-the-line gaming GPU like NVIDIA’s RTX 5090 (under $2500), anyone can locally run models matching the absolute frontier of LLM performance from just nine months ago. This lag is consistent with our previous estimate of a 5 to 22 month gap for open-weight models of any size. We find that leading open models runnable on a single consumer GPU typically match the capabilities of frontier models after an average lag of 9 months. This relatively short and consistent lag means that the most advanced AI capabilities are becoming widely accessible for local development and experimentation in under a year.
Diese Lücke macht lokale KI-Integration planbar. Innerhalb eines Jahres bekommt man aktuell Modelle, die die Qualität heutiger Top-LLMs erreicht.
"AI first"
Sangeet Paul Choudary über AI First:
what it means to be architecturally-native to a new technology i.e. rebuilding your system around the logic of a new technology, not merely using it. Four shifts mark such system redesign:Atomic Unit Shift: Redefine the smallest unit of value. Figma (cloud-native) reimagined design work around the design element while Adobe was stuck to the logic of the file Roblox treats interactable experiences, not static games, as its atomic unit, allowing creators and players to co-create persistent worlds.Venetian trade shifted risk management from “chest of coins” to “ledger entry,” enabling credit, insurance, and scale.Stripe treats the API call as its atomic unit, turning payments from bespoke integrations into composable building blocks.Constraints as Design: Embrace limits as features.Containers’ fixed sizes standardized global logisticsTelegraph bandwidth created coded tickers/time-tables that synchronized rail networksTikTok embraced the constraint of ultra-short video length, which optimized its algorithmic discovery loop and drove a new logic for the feed.
Datenpunkte, wie KI das Web verändert
Spannende Daten.

A handful of major AI companies hire and control their own fleet of media, because companies realise that what can set them apart is access to original content (studio model of AIs). Everything that depends on traffic is threatened, including high quality journalism (see Azeem’s discussion with The Atlantic CEO Nicholas Thompson • Cloudflare controls ~20% of global web (based on 45M HTTP requests/s) • Cloudflare live -> 71.6% human; 28.4% bot (26th Sept) AI crawlers account for 80% of all bot traffic, with 18% YoY growth • Training traffic: 79-80% (up from 72%); Search traffic: 17% (down from 26%) • User actions: 3.2% (up from 2%) Crawl-to-referral imbalance: • Anthropic shows a 38,065:1, OpenAI 1,091:1, and Perplexity 195:1 • Agents generate up to 39,000+ requests per minute during peak usage • Reports of AI crawlers returning every 6 hours -> creating DDoS-like loads Anthropic’s Model Context Protocol launched in November 2024 • OpenAI adopted MCP in March 2025; Google DeepMind confirmed support in April 2025; Microsoft created an official C# SDK. • 4.3k MCP servers on github
Ich habe die Links zu den Quellen entfernt, weil es Tracking-Links von Substack waren. Links zu den Quellen findet man auf Exponential View.
📺 Medienwandel und vernetzte Öffentlichkeit
Das Ende der Hashtags
Why? Platforms don’t need them anymore. “As a type of metadata, [the hashtag] wasn’t controlled by a platform—it was created by the people, for the people,” Linguistics creator Adam Aleksic wrote in his most recent Substack essay, “Why platforms are killing the hashtag.” “By removing the hashtag, tech platforms are redistributing organizational power away from the users and toward themselves.” Big picture: Platforms have more recently focused on improving their search bar functionalities, rendering hashtags less impactful on overall performance.
Die Macht der Plattformen wird nicht nur den Wegfall der Hashtags sich verschieben, KI-Fähigkeiten machen die großen Plattformen immer undurchsichtiger.
Man vergleiche das hier direkt miteinander: Indem Hashtags verwendet werden, ordnen sich User selbst Gruppen zu. Auf LinkedIn ist der Wegfall von Hashtags wie "#B2B" egal. Aber was ist mit "#blacklivesmatter" oder "#metoo"?
Letztere Bottom-up-Gruppierungen werden ohne Hashtags unmöglich.
Ich gehe davon aus, dass wir ähnliche Verschiebungen an vielen Stellen dank KI bei den großen Plattformen sehen werden.
Eine Folge davon: Die Plattformen werden immer stärker auch vom Vibe her wie Entertainment-TV.
Das öffnet langfristig auch Chancen für Neues.
✴️ Mehr Wissenswertes
Bagel Labs’ “Paris” trains text‑to‑image via fully decentralized experts via Venturebeat:
Why it matters: Paris swaps giant synchronized clusters for eight independently trained diffusion experts and a small router, claiming comparable image quality with ~14× less data and ~16× less compute than a prior decentralized baseline. The appeal is obvious: Train on heterogeneous, scattered GPUs without InfiniBand; deploy with open weights. The catch: Routing and partitioning become your new dark arts.
Ich bin bei so etwas immer vorsichtig, aber das hier wäre ein sehr großer Deal.
Dwarkesh Patel, bester und wichtigster KI-Podcaster (Economist jüngst hilarious: "Did you listen to the new Dwarkesh?") über sein Interview mit Sutton.
Some Thoughts on the Sutton Interview:
LLMs aren’t capable of learning on-the-job, so we’ll need some new architecture to enable continual learning. And once we have it, we won’t need a special training phase — the agent will just learn on-the-fly, like all humans, and indeed, like all animals. This new paradigm will render our current approach with LLMs obsolete. AlphaGo (which was conditioned on human games) and AlphaZero (which was bootstrapped from scratch) were both superhuman Go players. AlphaZero was better. Will we (or the first AGIs) eventually come up with a general learning technique that requires no initialization of knowledge - that just bootstraps itself from the very start? And will it outperform the very best AIs that have been trained to that date? Probably yes. But does this mean that imitation learning must not play any role whatsoever in developing the first AGI, or even the first ASI? No. AlphaGo was still superhuman, despite being initially shepherded by human player data. The human data isn’t necessarily actively detrimental - at enough scale it just isn’t significantly helpful. Even if Sutton’s Platonic ideal doesn’t end up being the path to first AGI, he’s identifying genuine basic gaps which we don’t even notice because they are so pervasive in the current paradigm: lack of continual learning, abysmal sample efficiency, dependence on exhaustible human data. If the LLMs do get to AGI first, the successor systems they build will almost certainly be based on Richard’s vision. . As planes are to birds, supervised learning might be to human cultural learning.
Please let the robots have this one • The Argument Mag:
But even in San Francisco where Waymos are a reality, I still run into a lot of Waymo haters. Sometimes they hate the cars for taking jobs from Uber and Lyft drivers. (Though remember how a couple of years ago everyone wanted to ban Uber and Lyft?) Sometimes they hate the cars out of vague anti-corporate sentiment. But often, what they really hate isn’t Waymo at all.
Rausschmeißer der Woche
Ethan Ding: In 100 Years, People Will Marvel at the Idea That...:
in 100 years, people will marvel at the idea that business logic in systems of record ever had a moat, or produced margins [like railroads] we are in a closing window of time where demand for software [logic] has allowed tech companies to make 80% margins for ~2 decades no tmrethan ding 📊 @TheEthanDingsystems of records will not have a moat in 10 years the writing is on the wall for those paying attention everything is compute
~
Briefing 271: ASML + Mistral, Dia + Atlassian, Cash + Onlinehandel, OnlyFans 8 Sep 9:14 AM (last month)
Das ist mal eine Neuigkeit, die es in sich hat: Laut Quellen von Reuters ist ASML dabei, bei Mistral mit umgerechnet 1,5 Milliarden $ einzusteigen und der größte Anteilseigner beim Pariser Startup zu werden.
Wenn das eintrifft, wird das die für Europa mit Abstand wichtigste Wirtschaftsnachricht mindestens des Jahres.
- Europa braucht ein eigenes, starkes, sprich nachhaltig eigenständiges Ökosystem in KI.
- Das im Vergleich zu seinen Peers stark unterfinanzierte Mistral ist mit großem Abstand der wichtigste Modellanbieter in Europa. (Mir fällt sogar außer Universitäten niemand Nennenswertes mit eigenen Modellen in Europa ein; Llama/Qwen/Deepseek-Finetunes zählen nicht.)
- ASML aus den Niederlanden ist eines der zwei weltweit wichtigsten Unternehmen, ohne welche die Weltwirtschaft aufgeschmissen wäre:
- TSMC in Taiwan baut 70%(!) aller global verbauten High-Tech-Chips.
- 100%(!) dieser Chips werden mit Lithographiesystemen von ASML hergestellt.
- Zwischen Lithographiemaschinen und KI-Modellen liegen mindestens zwei separate Wertschöpfungsebenen: Chipdesign (think Nvidia) und Chipherstellung (oben genanntes TSMC). (Und dann braucht es im Grunde mindestens noch jemanden, der die Chips in einem Datencenter verbaut.)
- Vielleicht ist nur Wunsch Vater des Gedankens, aber ich gehe davon aus, dass der Einstieg bei Mistral der Auftakt einer neuen strategischen Ausrichtung von ASML ist. Im Idealfall wachen auch andere europäische Riesen auf.
Unter anderem bietet diese Entwicklung uns allen in ein paar Tagen eine einzigartige Möglichkeit, die Qualität unserer Mediendiät zu überprüfen. Welche europäischen Wirtschaftsmedien werden, wenn es offiziell ist, das weit hinten vermelden? :)
LFG,
Marcel
Im Fokus dieser Ausgabe:
- Transformer können mehr als Sprache
- The Browser Company (Dia) geht an Atlassian und damit Richtung B2B und Arbeitsalltag
- Synthetische Daten für Robotik und Maschinenbau, enorme Chancen für Deutschland
- KI-Browser Fellou verschleiert Herkunft aus China
- Die immensen Cash-Reserven der vor allem chinesischen Onlinehandelsriesen
- OnlyFans ist groß genug, um die nächste Mainstream-Plattform werden zu können
- und mehr
Zitat des Tages
Amusing how 99% of people trying to explain LLMs forget that they don't generate the next token, they generate a probability distribution over the entire vocabulary space that the end application is free to sample from
You are very often not presented with the Most Likely Token
Amusing how 99% of people trying to explain LLMs forget that they don't generate the next token, they generate a probability distribution over the entire vocabulary space that the end application is free to sample from
— emozilla (@theemozilla) September 5, 2025
You are very often not presented with the Most Likely Token https://t.co/7RMM4KkeDo
🤖 KI
Was kann ein Token sein?
LLMs sind KI-Modelle, bei denen die Tokens, die kleinsten Sinneinheiten, aus Sprache bestehen. Das muss aber so nicht sein. Transformer-basierte KI-Modelle werden mittlerweile auf unterschiedlichste Datenarten angewandt.
Huawei und Google haben beide bereits mit der Transformer-Architektur Wetter-Modelle erstellt, die nicht nur präziser sind, sondern auch noch weniger rechenintensiv als die alten statistischen Modelle.
Die große Frage, die sich damit stellt, ist, über welche weiteren Datenarten man den Attention-Mechanismus der Transformer-Modelle jagen kann.

Die Frage für Unternehmen lautet nun, welche Arten von Daten im Alltag eingesetzt werden, die eine KI wie eine Sprache erlernen könnte.
The Browser Company (Arc, KI-Browser Dia) geht an Atlassian (horrible SaaS)
Das hatte sicher niemand auf der Bingo-Karte: Atlassian, weltweit seit über 20 Jahren rund um den Globus geliebt für Jira und Confluence, wird The Browser Company, die Macher von Dia, übernehmen, für 610 Mio. Dollar. (CNBC)
The Browser Company:
- Ist ein bisschen Opfer ihres eigenen Timings geworden. Das kann man nicht immer steuern. Ihr erster Browser Arc begann vor dem großen KI-Durchbruch. Der zweite Anlauf, der KI-Browser Dia, kam nachdem Arc nicht genug User fand. (Arc bleibt das beste Browser-Interface.) Da gab es das Startup aber bereits 5 Jahre.
- Das Startup hat das beste UI/UX-Team der letzten 10 Jahre. Das ist und bleibt eine gute Ausgangslage in der heutigen Welt, in der wir enorm mächtige Technologie haben (KI), die weiterhin hinter dem Terminal (Chat) darauf wartet, von den Nutzer:innen entdeckt zu werden.
- Es gibt also unfassbar viel ungehobenes Potenzial beim Thema UI für KI.
Atlassian:
- Ist eines der ältesten B2B-SaaS-Unternehmen der Welt.
- Jira und Co. sind das Gegenteil von dem, was die Dia-Macher gezeigt haben. Ein UI, das niemand mag, aber alle benutzen müssen.
- Wichtiger aber: Atlassian sieht wie alle den KI-Layer am Horizont aufziehen. Der kann sich über alles legen, auch und gerade über SaaS. Damit kann beispielsweise das Onboarding neuer Mitarbeiter:innen für Unternehmen einfacher werden.
- Es hilft sicher enorm, dass der CEO von Atlassian ein Superfan von Arc und Dia war.
Mike Cannon-Brookes, the CEO of enterprise software giant Atlassian, was one of the first users of the Arc browser. Over the last several years, he has been a prolific bug reporter and feature requester. Now he’ll own the thing: Atlassian is acquiring The Browser Company, the New York-based startup that makes both Arc and the new AI-focused Dia browser. Atlassian is paying $610 million in cash for The Browser Company, and plans to run it as an independent entity.
The conversations that led to the deal started about a year ago, says Josh Miller, The Browser Company’s CEO. Lots of Atlassian employees were using Arc, and “they reached out wondering, how could we get more enterprise-ready?” Miller says. Big companies require data privacy, security, and management features in the software they use, and The Browser Company didn’t offer enough of them. Eventually, as companies everywhere raced to put AI at the center of their businesses, and as The Browser Company made its own bets in AI, Cannon-Brookes suggested maybe the companies were better off together.
Gemeinsam: KI-Browser für B2B-SaaS:
Briefing 270: GPT-5, Media Saturn und JD, DeepSeek und chinesische Chips 1 Sep 8:33 AM (last month)
Hi,
man merkt an turbulenten Zeiten, dass es kein Sommerloch bei den Themen gibt.
Nach der Sommerpause gibt es einige Themen aufzuarbeiten. Heute gibt es deshalb unter anderem noch ein paar Anmerkungen zu GPT-5.
Noch ein Hinweis in eigener Sache: Das Briefing wird künftig wie heute Montags erscheinen und nicht mehr Freitags. Weitere Neuerungen dann in naher Zukunft.
Marcel
Im Fokus dieser Ausgabe:
- Die Kosten und das User-Interface von GPT-5 werfen Fragen zur Differenzierung von KI-Produkten auf.
- Auch: GPT-5 im Pro-Modus ist mächtig. Und: Preisgestaltung und das Interface von GPT-5 sind für professionelle Nutzer:innen weiterhin problematisch.
- KI in der Bildung: Eindeutig sinnvoll.
- Sicherheitslücken bei KI-Browsern wie Comet zeigen neue Risiken für Nutzer:innen und ihre Daten.
- Die Übernahme von Media Saturn durch JD könnte den Anfang einer neuen Ära bedeuten für den deutschen Handel. Vor allem, weil in China Geld vorhanden ist, das ohne Probleme große deutsche Unternehmen aufkaufen kann.
- Agentic Commerce verändert die Rolle von Daten und Marktplätzen im Onlinehandel grundlegend.
- DeepSeek und chinesische Chips.
- Solar wird sich global mindestens vervierfachen bis 2030.
- und mehr
Zitat des Tages
At some point the meaning of ‘driving’ and ‘self-driving’ will invert.
At some point the meaning of ‘driving’ and ‘self-driving’ will invert.
— ZΞfi (@zefi) August 5, 2025
🤖 KI
GPT-5, Kosten und Router
So viel Gegenwind, dass es ein Abendessen mit Journalist:innen in San Francisco gab, bei dem Altman und weitere Executives von OpenAI on the record(!) Fragen beantworteten. Eine Folge, wenn nicht nur das eigene Produkt zu den erfolgreichsten der Menschheitsgeschichte gehört, sondern das eigene Marketing noch einen draufsetzt (AGI?).
Sam Altman hat in Interviews mit The Verge und Axios ungewöhnlich offen Fehler beim Launch von GPT-5 eingeräumt: OpenAI habe „einige Dinge total vermasselt“, insbesondere beim Wechsel des Standardmodells und der Kommunikation mit den Nutzer:innen. Während der Launch für Endkund:innen eher durchwachsen verlief, verdoppelte sich wohl das API-Volumen in kurzer Zeit. OpenAI stößt inzwischen an die Grenzen der verfügbaren GPUs. Altman betonte, dass er aus dem Rollout gelernt habe, was es bedeutet, ein Produkt für Hunderte Millionen Menschen über Nacht zu ändern. (The Verge)
Ich schätze, dazu zählen bahnbrechende Erkenntnisse wie, dass man zahlenden Kund:innen nicht ohne Ankündigung Features wegnimmt.
Etwas, das in meinen Augen offensichtlich ist, ich aber erstaunlicherweise bisher nirgendwo gelesen habe:
Es ergibt keinen Sinn, dass ein Produkt, das 200$ pro Monat kostet, das exakt gleiche User-Interface hat wie ein kostenfreier (bald werbefinanzierter) Mainstream-Service.
Dass OpenAI an einem Dropdown-Menü scheitert und davon ausgeht, dass sich KI-Produkte über alle Preissegmente hinweg vor allem nur in Nutzungsgrenzen und im Zugang zu besseren Modellen unterscheiden, ist wirklich bemerkenswert.
Product people, where art thou.
Der Router
Das Wichtigste an GPT-5 ist der Router, das eigentliche Produkt, das hier eingeführt wurde. Ein vorgelagertes Modell, das die Anfrage analysiert und dann zum schnellen, kostengünstigeren, leichteren Modell oder zum Thinking-Modell leitet. Anstatt kryptischer Modellnamen.
Das ist einerseits die richtige Entwicklung, andererseits problematisch:
- Die Blackbox LLM wird im B2C-Bereich damit noch blackboxiger. Weil eine vorherige Auswahlmöglichkeit durch einen weiteren Automatismus ersetzt wird.
- E gibt hier einen Interessenskonflikt: OpenAI steuert mit dem Router, welche Kosten ihnen eine Anfrage verursacht. Geringere Kosten = geringere Qualität des Outputs. OpenAI kann ohne, dass die User das nachvollziehen können, die Hebel im Hintergrund Richtung Qualität oder Kosten umlegen.
- Beides, Black Box und Interessenskonflikt, kamen direkt im Launch von GPT-5 zusammen: Augenscheinlich war der Router zu sehr auf Kostenersparnis/Geschwindigkeit geeicht. Das machte GPT-5 für viele User "dümmer". Das Unternehmen behauptete dann, dass es sich um einen Fehler gehandelt habe. Ob das stimmt, wissen wir nicht.
Die Spannung zwischen Komplexität der Technologie und Zugänglichkeit des Interfaces ist ein permanenter Balanceakt; der bei LLMs noch diffiziler geworden ist.
These: LLM-Produkte werden heute immer noch gebaut wie klassische Software, brauchen aber ein grundlegend neues UX-Paradigma. Weil LLMs viel komplexer und idiosynkratischer sind als jeder andere Software-Baustein.
Die Kosten
ChatGPT hat über 700 Millionen wöchentlich aktive Nutzer:innen. (Monatlich aktive Nutzer:innen dürften bei über einer Milliarde liegen.)
Neben leistungsfähigeren Modellen hat hier vor allem der Kostenfaktor eine hohe Priorität für das Unternehmen.
Anthropics Modelle sind oft gleichauf mit OpenAI, oder besser, aber nahezu immer teurer weil rechenintensiver (lies: weniger effizient). Das macht sich in Nutzungslimits bei Claude selbst oder bei Claude in Cursor bemerkbar. OpenAI kann sich das bei seiner Nutzerzahl, B2C wie B2B, schlicht nicht leisten. Wortwörtlich.
GPT-5 Standard ist ungefähr halb so teuer wie GPT-4o. (Das für ChatGPT nicht relevante Modell GPT-5 nano ist bis zu 90% günstiger.)
Der große Endgegner für OpenAI neben den offenen Modellen aus China ist Google. GPT-5 liegt preislich ungefähr auf Niveau von Googles Gemini 2.5 Pro (Basis). Google profitiert hier von seinem vertikal integrierten Techstack bis hin zu den eigenen KI-Chips.
Das Wachstum der Google Cloud Platform, Googles Cloud-Angebot, profitiert enorm von den günstigen, leistungsfähigen Gemini-Modellen und kann aktuell nur so schnell wachsen wie sie die Datencenter ausbauen können.
Mehr Nachfrage als Angebot. It's a theme.
GPT-5-Qualität
Zunächst: GPT-5 ist ein Opfer des überbordenden Marketings der KI-Startups. Viele haben erwartet, dass OpenAI beim "Versionssprung" von 4 auf 5 etwas ähnliches liefert wie von 3 auf 4. Das war aus einem einfachen Grund unmöglich:
Wettbewerb.
OpenAI, Anthropic, Google und die chinesischen Labs (und mit Abstrichen Mistral) liefern sich ein konstantes Kopf-an-Kopf-Rennen, wer aggressiven Sichern von Marktanteilen mit dem qualitativ besten (und bezahlbaren!) Modell am Markt vorn liegt. Herrscht bei einem Lab für mehr als vier Monate Stille, gehen die Gerüchte los. KI ist immer noch ein (gemessen am Potenzial) vergleichsweise kleiner, aber sehr rasant wachsender Markt. Das erzeugt Druck:
- Sowohl beim Launch von GPT-5 als auch bei Claude im Coding-Sektor: Modelle entwickeln langsam Stickyness bei Powerusern, entweder emtionaler Art wie bei 4o (hochproblematisch), oder auf andere sanfte, nicht quantifizierbare Arten wie Claude im Programmierbereich. (Marktanteile von Claude schwanken
- Talent spielt (mehr oder weniger aradoxerweise) immer noch eine große Rolle im KI-Sektor. Labs, die wahrgenommen werden als nicht an der Speerspitze zu stehen, können Leute schneller verlieren oder, schwerwiegender, nicht neue Toptalente anziehen. (U.a. Metas Problem vor dem Reorg.) Die Nachfrage ist größer als das Angebot. Nicht nur bei der KI-Nutzung, sondern auch bei den KI-Forschenden.
- Die Früchte bei der Technologieentwicklung hängen noch immer tief genug, so dass kein KI-Lab lang an der Spitze der Benchmarks bleibt. Alle werden konstant inkrementell besser.
-> Aus all dem folgt, dass kein Anbieter es sich leisten kann, mehr als eine Generation neuer Modelle zurückzuhalten, nur damit der Marketingsplash größer ist. In Sam Altmans Traumwelt hätten sie auf alle Reasoningmodelle verzichten können und nach einem dreiviertel Jahr Ruhe mit GPT-5 um die Ecke kommen können. BUT ALAS.
Der Unterschied zwischen der ersten Version von GPT-4 und dem heutigen GPT-5-System ist riesig. Und zwischen beiden liegen lediglich zwei Jahre.
(Im Grunde war das erste Reasoning-Modell von OpenAI der eigentliche Nachfolger von GPT-4, also GPT-5 im Geiste.)
Epoch AI hat das anhand des Math-Benchmarks grafisch aufbereitet:
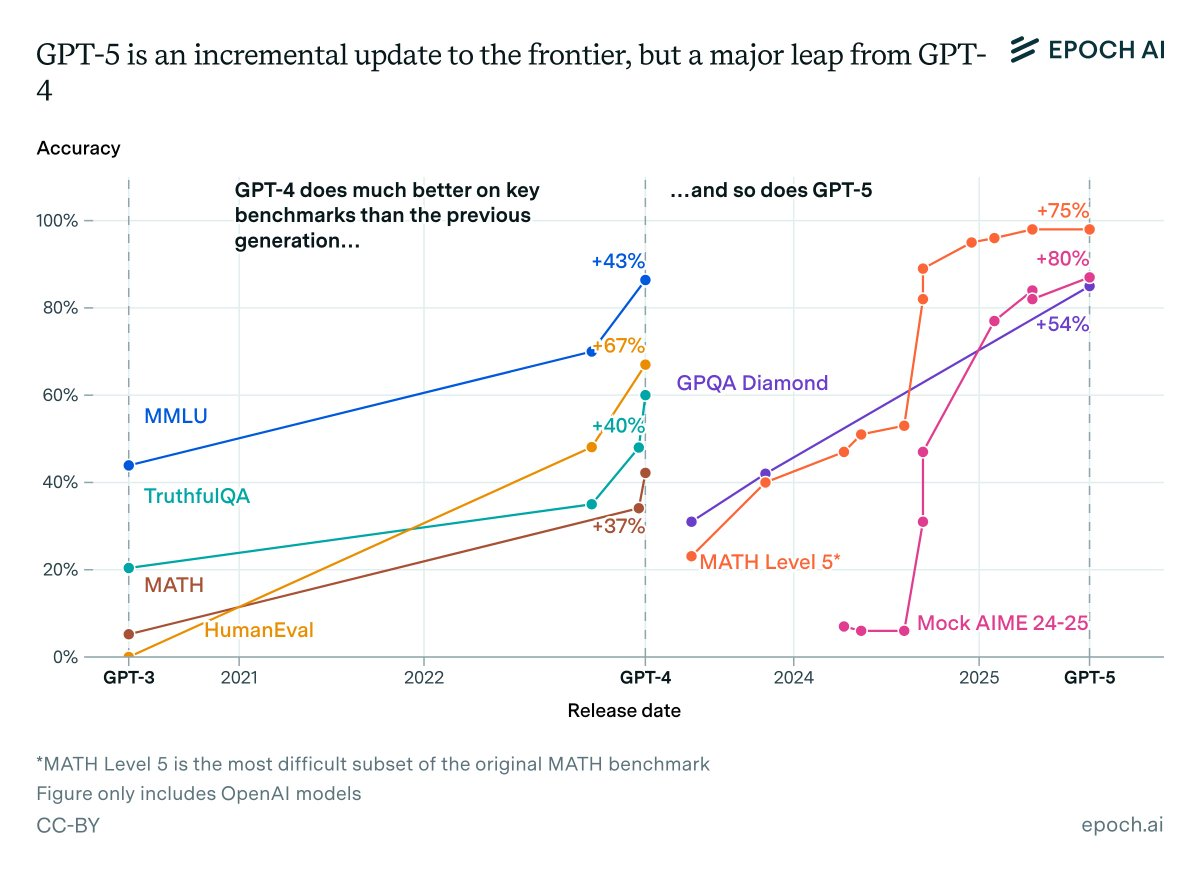
Aber das ist alles nicht wirklich entscheidend. Relevanter ist die Frage, ob mit GPT-5 neue Dinge möglich sind.
GPT-5 ist, zumindest im teuersten Pro-Modus, sehr mächtig. Erste Top-Forscher:innen sind richtig aus dem Häuschen.
Als Beispiel schauen wir auf die Aussagen von Dr. Derya Unutmaz. Unutmaz ist einer der führenden Immunologen weltweit. Für den Kontext hier sein Scholar-Profil:
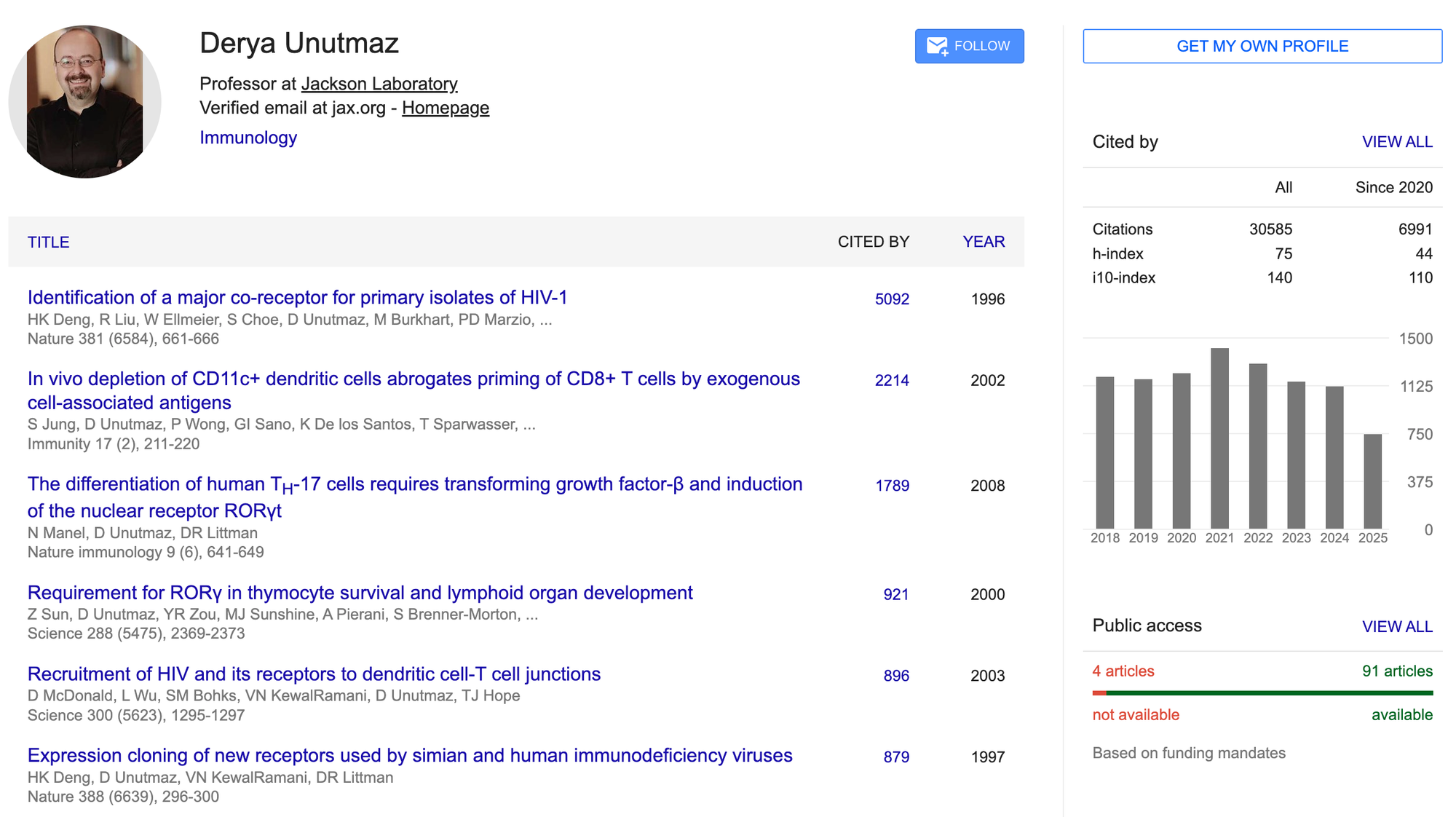
Unutmaz hat GPT-5 anhand unveröffentlichter Studiendaten getestet. Das Modell hat die gleichen Ergebnisse aus den Daten produziert wie das hochkomplexe Experiment:
In a social media post, Unutmaz revealed that he used GPT-5 to predict the results of a month-long, highly complex experiment aimed at engineering cells to fight lymphoma. The AI’s predictions, he said, were “astonishingly accurate”. [...]
Unutmaz noted that GPT-5 not only forecasted the entire experimental process and results with high precision, but also suggested design improvements.

Er schreibt auf X auch:
At this point, I may have to revise my timeline for curing aging to a date earlier than the 2040s!
Doubt no more. Thanks to AI, we will treat all diseases and reverse aging!
Unutmaz wurde nach diesen Aussagen von OpenAI direkt für ein Werbevideo eingesetzt.
Ebenfalls ein gutes anschauliches Beispiel für die Planungsfähigkeiten von GPT-5 hat Ethan Mollick hier aufgeschrieben:

If you didn’t catch the many tricks - the first word of each sentence spells out the phrase This is a Big Deal, each sentence is precisely one word longer than the previous sentence. each word in a sentence mostly starts with the same letter, and it is coherent writing with an interesting sense of style. In a paragraph, GPT-5 shows it can come up with a clever idea, plan, and manage the complicated execution (remember when AI couldn’t count the number of Rs in “strawberry”? that was eight months ago).
Descript Underlord: KI-Videoeditor
Descript baut mit dem amüsant benannten "Underlord" einen KI-Videoeditor.
Möglich ist das, weil Descript bereits bekanntlich textbasierte Bearbeitung von Audio- und Videoinhalten anbietet. Das LLM-Feature kann über diesen bestehenden Weg auch direkt die Inhalte ändern.
Besser integrierte LLMs, wenn die notwendige Basis dafür bereits gelegt wurde. This is the way.
KI in der Bildung
Sascha Lobo schreibt auf Spiegel über KI an Schulen.

Wir hatten eine der wichtigen Metastudien zu KI in der Bildung hier bereits im Briefing. Es lohnt sich aber, auf die Forschungsergebnisse zu KI in Bildung noch einmal hinzuweisen, weil es so wichtig ist.
Metastudien finden eindeutige positive Effekte bei richtigem Einsatz:
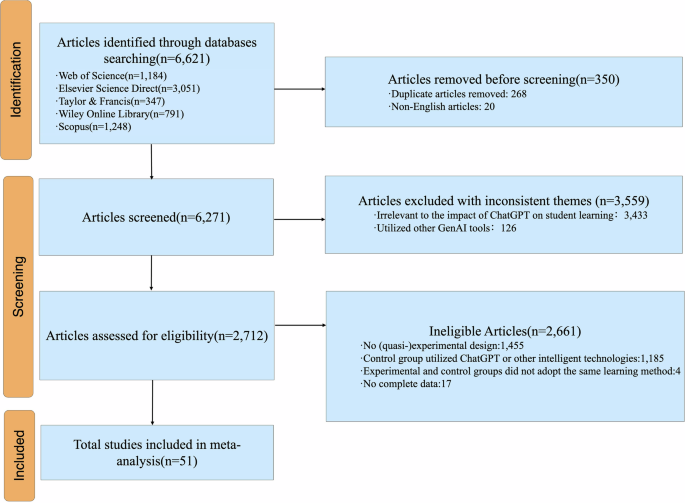
Die Technologie kann natürlich falsch oder richtig implementiert werden. Auf die Frage, ob KI sinnvoll im Bildungswesen eingesetzt werden kann, antwortet die Forschung eindeutig: Ja.
Ich nutze für Recherchen von akademischen Papern ab und an Consensus. Das aggregierte Ergebnis dieses Recherchewerkzeugs ist, zusätzlich zu ebenfalls eindeutig:
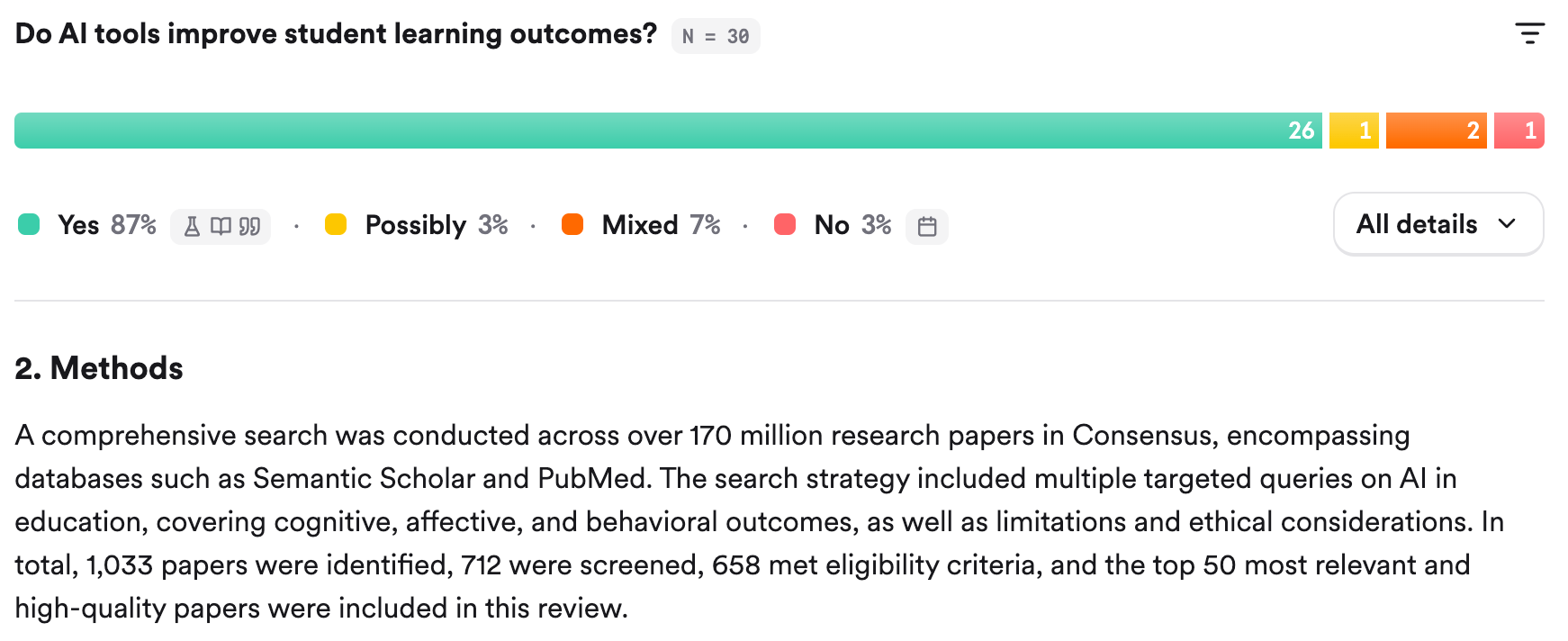
Saschas Kolumne zur KI-Pflicht ist also weniger kontrovers als ein No-Brainer. Zumindest, wenn man sich an der Forschung zum Thema orientiert.
Und last not least besonders wenn man bedenkt, wie KI in Rekordzeit unseren Alltag durchdringt. Augen zuhalten und Erlkönig auswendig lernen allein wird nicht reichen.
Es gibt nur 7 KI-Apps
Briefing 269: Sommerlektüre 7 Aug 10:30 PM (2 months ago)
Hi,
wir sind mitten in der Sommerpause. Deshalb ein etwas anderes Format, mit Schwerpunkt auf Lesetipps und Kommentaren meinerseits. Nächste Woche wird kein Briefing erscheinen. Das nächste Briefing erscheint in zwei Wochen am 22. August. Dazwischen wird es je nach Lage eventuell einzelne Texte auf neunetz.com geben. Kurze Texte werden nicht per Email verschickt.
Wer es verpasst hat, ich habe mit Sascha Lobo über KI-Browser gesprochen. Ein paar weitere Gedanken dazu habe ich hier aufgeschrieben.
Marcel
Lektüretipps, Zitate und Anmerkungen zu:
- Ökonomie der Superintelligenz
- Wie würde überhaupt geopolitische Unabhängigkeit bei KI für uns aussehen?
- Wie sich Chinas KI-Ansatz von den USA unterscheidet und warum das so ist
- Datencenterausbau -> Finanzkrise?
- TikTok Shop in Deutschland
- Buchempfehlungen
- und mehr
Nicht nur die akademische Welt:
Die Ökonomie der Superintelligenz

Die Ökonomie der Superintelligenz: Was passiert, wenn KI wirklich „alles" oder zumindest fast alles kann?
Der Economist stellt sich in einem jüngeren Titelbriefing die Frage, der sich in Europa die Eliten noch nicht wirklich zu stellen scheinen: Was, wenn die Voraussagen aus dem Silicon Valley bezüglich KI-Entwicklungen ansatzweise zutreffen?
Ich war seit Ende 2022 (wie der Rest der Welt) beeindruckt, was bei KI passiert, aber verhalten bis skeptisch, was die Voraussagen anging. Seit ich intensiver Insidern der Branche als auch der Forschung folge (ich mache einmal im Monat einen Überblick über KI-Forschung für die FAZ), ist meine Skepsis dem bedrückenden Gefühl gewichen, dass vor unseren Augen die Basis für eine neue Wirtschaftsordnung entsteht, die bis jetzt nahezu komplett an Europa vorbeigeht.
Die Dringlichkeit der Lage wird nur in den USA erkannt -wo die Hyperscaler historische CapEx-Rekorde aufstellen und in den Quartalsberichten mitteilen, dass Nachfrage kontinuierlich höher ist als ihr Angebot wie jüngst Google mit Ausgaben, Status Quo und Aussichten für GCP. Und in China, das sich mit Alibabas Qwen, den DeepSeek-Modellen und jüngst Kimi K2 von Moonshot an die Speerspitze der "offenen" KI-Modelle gesetzt hat. (Offen heißt hier: Kann leichter angepasst werden und kann auf eigenen Servern betrieben werden. Kein Tag mehr, an dem kein Konzern ein weiteres eigenes Deepseek- oder Qwen-Finetune verkündet.)
Wie dem auch sei, die Signale aus der Forschung und aus den Labs sind eindeutig, die Nachfrage gemäß der Quartalszahlen der Hyperscaler ebenfalls. Die Qualität der jüngsten Modelle und die ersten für den Alltag benutzbaren Agenten-Produkte auch.
Wir brauchen nicht "AGI" für umwälzende Veränderungen. Es reicht eine Entwicklung mit vergleichbarer Geschwindigkeit. (Es würde sogar bereits der heutige Stand und mehr Fokus auf Produkte, Dienste und Interfaces reichen für umwälzende Veränderungen in den nächsten 10-20 Jahren.)
Wie dem auch sei. Der Economist hat sich an der sehr schwierigen Frage versucht, was konkret passiert, wenn KI zu explosionshaftem Wachstum führt.
UNTIL 1700 the world economy did not really grow—it just stagnated. Over the previous 17 centuries global output had expanded by 0.1% a year on average, a rate at which it takes nearly a millennium for production to double. Then spinning jennies started whirring and steam engines began to puff. Global growth quintupled to 0.5% a year between 1700 and 1820. By the end of the 19th century it had reached 1.9%. In the 20th century it averaged 2.8%, a rate at which production doubles every 25 years. Growth has not just become the norm; it has accelerated.
If the evangelists of Silicon Valley are to be believed, this bang is about to get bigger. They maintain that artificial general intelligence (AGI), capable of outperforming most people at most desk jobs, will soon lift annual GDP growth to 20-30% a year, or more. That may sound preposterous, but for most of human history, they point out, so was the idea that the economy would grow at all.
Einer der wichtigen Punkte ist die Tatsache, dass Kapital, also die Möglichkeit in Produktionsanlagen zu investieren, wichtiger wird:
If you add machines but not workers, capital lies idle. But if machines get sufficiently good at replacing people, the only constraint on the accumulation of capital is capital itself.
Suppose production was fully automated, but technology did not improve. The economy would settle into a constant rate of growth, determined by the fraction of output that was saved and reinvested in building new machines.
Das scheint mir ein Punkt zu sein, der von vielen ausgeblendet wird, die behaupten, wir sehen mit KI lediglich die Wiederholung der Industrialisierung mit ihren Automatisierungen körperlicher Arbeit. Denn das trifft eben nur zum Teil zu. KI wird mindestens punktuell menschliche Arbeit komplett aus einzelnen Wertschöpfungsebenen herausziehen.
Der Unterschied zwischen 90% und 100% Automatisierung einer wirtschaftlichen Tätigkeit hat stärkere Implikationen für Wirtschaft und Gesellschaft als die Differenz eines Automatisierungsgrades (oder Augmentierungsgrades) einer solchen Tätigkeit von 10% zu 90%.
(Selbst hochgradig automatisierte Fabriken brauchen spezialisierte Ingenieur:innen, die sich um Steuerung und Wartung kümmern. Übrigens ein Grund, warum Manufacturing weltweit, selbst in China, als Jobmarkt auf dem Rückmarsch ist: Fertigung ist heute immer stärker eine hochspezialisierte Domäne für wenige, gut ausgebildete Menschen.)
Eine Prognose im Economist laut einem Paper ist, dass die Volkswirtschaft so schnell wächst, dass die im Vergleich langsamer wachsenden Gehälter trotzdem ansteigen:
In Mr Nordhaus’s paper, less-than-perfect substitutability between labour and capital during an AI breakout leads to an explosion in wages. Strangely, wages still shrink as a share of the economy, since the economy is growing even faster (see chart). There is some evidence of this dynamic already within tech firms, which tend to pay superstar wages to top workers, even though the share of such firms’ income that goes to owners is unusually high.
Hier zeigt sich, wie "Wirtschaftswachstum" in der Öffentlichkeit oft missverstanden wird. Wachstum vergrößert den Kuchen, die Gründe sind vielfältig, überhaupt nicht zwingend steigender Ressourcenabbau. Und der Kuchen selbst besteht aus vielen beweglichen Teilen, die sehr unterschiedlich auf einander reagieren.
Neben der wachsenden Bedeutung von Kapital steigt auch die Ungleichheit am Arbeitsmarkt, weil einzelne Tätigkeiten mit KI produktiver werden:
Averages conceal variation. Explosive wages for superstars would not console those with more mundane desk-jobs, who would have to fall back on the parts of the economy that had not been animated. Suppose, despite AGI, that technological progress in robotics were halting. There would then be plenty of physical work requiring humans, from plumbing to coaching sports. These bits of the economy, like today’s labour-intensive industries, would probably be affected by “Baumol’s cost disease” (a wonderful affliction for workers) in which wages would grow despite a lack of gains in productivity.
"that technological progress in robotics were halting": Wer hier im Briefing aufmerksam mitliest weiß, dass das nicht der Fall sein wird. Es wird mit Hochdruck an KI-Modellen für Robotik gearbeitet. China hat den Aufbau von heimischer (humanoider) KI-Robotik zu einem der höchsten Industriepolitik-Ziele erklärt. (Unitree freut's.)
Humanoide Robotik wird aber auf absehbare Zeit nicht „alles“ „überall“ ersetzen. Stattdessen wird es „Baumols cost disease“ noch verstärken.
Völlig unklar ist heute, wie sich Preisniveaus von Produktkategorien entwickeln werden:
Some worry that the Baumol effect would be so acute as to limit economic growth. When the price of something collapses, people buy more of it. But its share of consumer spending can still fall. Take food. In 1909 Americans bought 3,400 calories-worth of food per day (including waste), which cost 43% of their incomes. Today they buy 3,900 calories-worth, but that costs just 11% of their incomes. If prices fall faster than quantity increases, the measured economy becomes dominated by whatever it is that cannot be made more efficiently. “Growth may be constrained not by what we are good at but rather by what is essential and yet hard to improve,” wrote Mr Aghion and his colleagues.
Das trifft im Grunde auf fast alles zu: Relativ unklar, wie die volkswirtschaftlichen Effekte in Summe am Ende tatsächlich aussehen werden.
Umso wichtiger, dass auch hierzulande ernsthafte Debatten darüber geführt werden, was passiert, wenn die Prognosen aus den Labs zutreffen - und, last but most certainly not least wie wir es realistisch(!) beeinflussen können.
Unterschätzte KI
Ebenfalls im Economist:

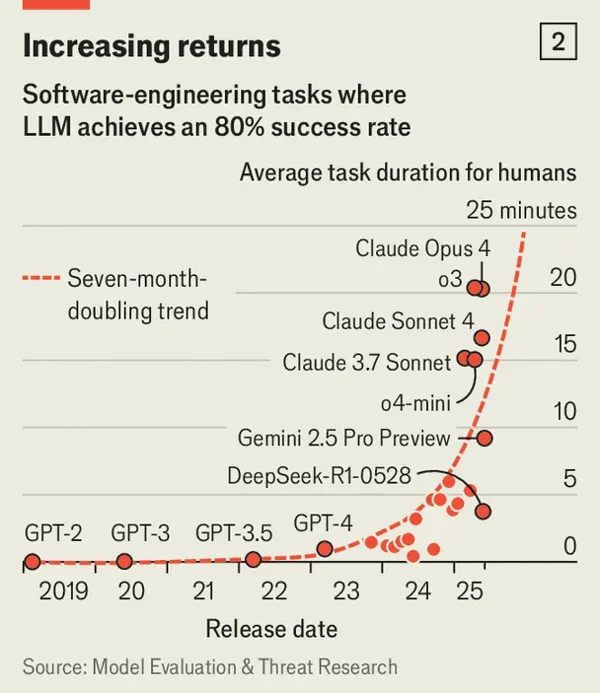
The boosters could, of course, be over-optimistic. But, if anything, such prognosticators have in the past been too cautious about ai. Earlier this month the Forecasting Research Institute (fri), another research group, asked both professional forecasters and biologists to estimate when an aisystem may be able to match the performance of a top team of human virologists. The median biologist thought it would take until 2030; the median forecaster was more pessimistic, settling on 2034. But when the study’s authors ran the test on Openai’s o3 model, they found it was already performing at that level. The forecasters had underestimated ai’s progress by almost a decade—an alarming thought considering that the exercise was designed to assess how much more likely ai makes a deadly man-made epidemic.
(Hervorhebung von mir)
Dazu passend auch diese Entwicklung:
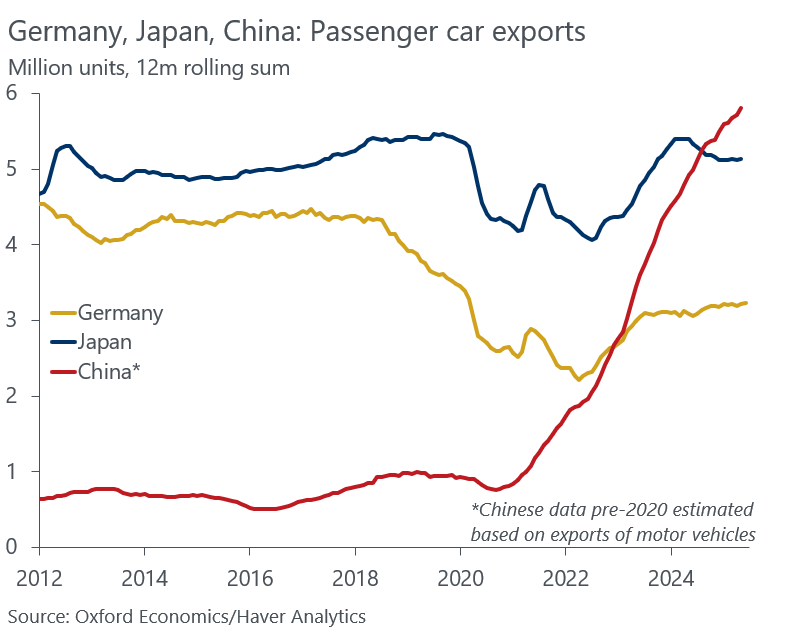
Als die deutsche Automobilindustrie sich vom Massenmarkt verabschiedete
Man sieht in diesem Chart hervorragend den Zeitpunkt, als sich VW und die anderen deutschen Automobilkonzerne mit Ansage auf die Marge zu konzentrieren begannen und den Massenmarkt damit aufgaben.
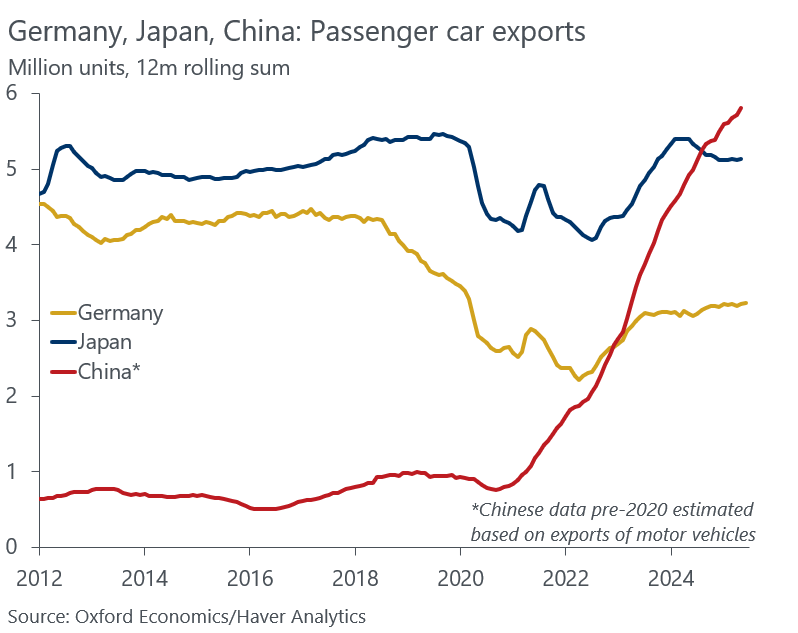
Selbst Japan liegt heute höher und China scheint gerade erst anzufangen.
Wie immer bei diesem Thema: Software-Plattformen und Services entstehen auf einer breiten Hardware-Basis. Wer diese nicht hat, hat auch keine Chance auf, zum Beispiel, softwarebasierte Geschäftsmodellinnovationen.
(Hinzu kommen alle Folgen der größeren Vielfalt an Formfaktoren dank E-Antrieb. Metropolenlieferungen via E-Bikes und E-Scooter-Sharing waren da erst der Anfang.)
Geopolitische Unabhängigkeit und KI
Sehr wichtiger und lesenswerter Beitrag von Marcel Salathé zur Frage, an welchen Stellen der Wertschöpfungskette bei KI wir uns unabhängig machen können und machen sollten.
Zu oft wird diese Frage als alles oder nichts debattiert, was einerseits unrealistisch und andererseits unernst ist.
Wir werden meiner Meinung nach nicht US-Top-Anbieter in KI-Modellen einholen und wir werden, mittlerweile, wohl auch eher nicht die offenen Top-Modelle aus China einholen. Das ist aber vielleicht auch gar nicht notwendig, wenn wir es schaffen eigene Ökosysteme und Branchen rund um offene Modelle zu bauen.
Wichtig ist hier ein pragmatischer Ansatz, um das Meiste aus KI herauszuholen.
Salathé spricht von einem Fokus auf „building and strengthening talent pipelines“, was sowohl Hochschulen als auch Ausgründungen aus diesen einschliesst:
At a recent talk I gave at the Swiss Software Festival, this was one of the key discussion points. I argued that for Switzerland (and I believe this holds true for virtually every country except the United States and possibly China), AI sovereignty doesn't exist. It's a pipe dream, an illusion. But it remains incredibly appealing, and its temptation might actually prevent us from focusing on more realistic goals.
To have sovereignty means possessing decision-making power and the agility to act independently. You essentially control your own destiny. A nation with AI sovereignty would be able to make decisions about AI development and deployment without external constraints, fully independently.
My contention is straightforward: outside of the United States and possibly China, no nation currently meets all these criteria.
Sein verfolgenswerter Ansatz:
Rapid adoption and innovation: With talent, you can quickly integrate leading AI technologies and build world-class products and services on top of existing platforms. Yes, selling GPUs is great business, but most wealth generation in AI in the long run will be in applications.
Localization and adaptation: Don’t like a limited offer of US and Chinese AI? Take global AI developments and adapt them to local contexts, values, and regulatory requirements. The Swiss LLM initiative exemplifies this approach, and is precisely the kind of targeted, strategic initiatives that make sense. Needless to say, this needs strong talent.
Education and research investment: Because talent is so central, your first task is in ensuring you maintain and expand talent pipelines through sustained investment in education and research infrastructure.
The path forward is clear, in my view: if small to mid-sized nations want to position themselves strategically in the AI era, they should prioritize talent sovereignty. Rather than chasing the illusion of complete AI independence, focus on building and maintaining the human capital that can thrive in an AI-transformed world.
Sein Fazit:
In the end, success in the AI age won't be determined by whether a country can produce its own chips or control its own compute infrastructure. It will be determined by whether it has the people capable of building remarkable things with the tools available to them. For that you need talent production, and thus investment in education and R&D.
Neben den volkswirtschaftlichen Folgen einer rapide besser werdenden KI ist das das zweite drängende wirtschaftliche Thema, mit dem sich die europäische Politik beschäftigen muss.
China hat einen sehr anderen KI-Ansatz als die USA
Dazu passend die Frage, wie man in China KI angeht und warum plötzlich von dort offene KI-Modelle kommen, die es mit den US-Modellen aufnehmen können.
Tech, KI & Schmetterlinge & KI-Browser 6 Aug 2:15 AM (2 months ago)

Was bedeutet es, wenn Browser plötzlich mitdenken, Rezepte automatisch in Warenkörbe übertragen oder Mails durchsuchen und sortieren können? Warum werden Plattformen wie Instagram oder LinkedIn nervös, wenn KI-Agenten auf ihre Web-Oberflächen zugreifen? Und: Ist der KI-Browser der Vorbote für das nächste große Interface – oder doch nur eine Brückentechnologie?
Eine Folge über Komfort, Kontrolle, Datenschutz – und darüber, wie überraschend lebendig der Browser 2025 wieder ist.

Das Gespräch knüpft nahtlos an das Briefing zum Thema an:
Ein interessanter Aspekt: Sascha wirft die berechtigte Frage in den Raum, ob die Suche nach dem KI-Gadget fehlgeleitet ist, weil es bei KI wie so oft die Software ist, die den Zugang definiert und dominiert, nicht die Hardware. Also Software statt Hardware. Also hier KI-Browser statt KI-Gadget von Jony Ive für OpenAI.
Das ist ein nachvollziehbarer und richtiger Gedanke. Der Siegeszug des Smartphones war schließlich genau das. Ein Computer in Taschenformat, der alles verschluckt hat, vom MP3-Player bis zur Digitalkamera, weil die Software die Hardware ersetzte. Und damit alles in einem Gerät vereinte.
Meine Entgegnung im Podcast-Gespräch: KI-first ist eine weitere Verschiebung des Paradigmas, weg von dedizierter Hardware (haben wir schon vollzogen) und jetzt (neu!) auch weg von dedizierter Software. Weil die KI über allem liegt. Und das wiederum bedeutet, dass die KI selbst, und damit die Cloud, im Mittelpunkt steht. (Weil die funktional umfangreichsten KI-Systeme in der Cloud sind, nicht lokal. Und das wird auch absehbar so bleiben.)
Daraus folgt unter anderem, dass Hardware und Software „nur“ Touchpoints zur KI werden. Wir hatten das und dessen Implikationen hier unter anderem bereits in Briefing 261 debattiert:

Nichts davon wird natürlich 100 Prozent der Nutzung erreichen. Es gibt heute immer noch Digitalkameras. Apps und Webdienste, die Menschen händisch bedienen, wird es natürlich immer weiter geben. Aber das Gros der Aktivität an vielen Stellen, vor allem Mainstream-Nutzung und Nicht-Expert:innen-Nutzung, wird von KI-Systemen gemanagt werden.
Hier spielen KI-Browser eine strukturell wichtige Rolle. Konzerne wie Google haben einen Vorteil, weil ihre Bots (in diesem Kontext quasi die Hände der KI) bestenfalls punktuell ausgesperrt werden.
Wenn ein Startup wie Perplexity eine Chance haben will, relevant zu werden -und dafür für Nutzer:innen nützlich sein muss-, dann wird es zwangsläufig alle diese Nützlichkeit verringernden Barrieren umgehen, die es umgehen kann. Dazu gehören leider auch freiwillige Dinge wie robots.txt:
Yes, this is not cool.
On the other hand, website owners are not going to cut out any search-related AI bot from Google thanks to its aggregation power.
How can an upstart gain any traction in this reality? At the very least, this is not a clear good/bad situation. It‘s messy. I find it fascinating.
Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives
Das zeigt uns also einen weiteren Grund, warum KI-Browser gebaut werden. Google kann seine KI-Bots aus der Cloud starten. OpenAI dürfte mit seinen mittlerweile 700(!) Millionen wöchentlich aktiven Nutzer:innen ebenfalls auf dem Weg sein, für viele Webdienste und Anbieter so wichtig zu werden, dass sie auszusperren zu hohen Opportunitätskosten führt. OpenAIs GPT-Agent kann also in der Cloud sitzen.
Das Gleiche gilt (noch?) nicht für Perplexity, Dia, Opera und alle weiteren.
Ich will diesen Grund nicht überbewerten -die Nützlichkeit für die Nutzer:innen ist viel wichtiger-, aber man sollte das auch nicht unterschätzen: Der Umweg über den lokalen Browser stellt den Zugang sicher. Wo ich hingehe, wo ich Accounts habe, wo ich das Abo zahle, dort ist auch meine KI mit meinem Browser drin. Damit wird der Browser mindestens für kleinere Anbieter ein wichtiger Baustein im KI-First-Angebot. Er ist nützlich für die User und er gibt der KI in der Cloud im Zweifel Zugänge über den lokalen Umweg, den die KI-Unternehmen in Form von Deals so schnell nicht bekommen würden. Im Idealfall wandern die Aufgaben und die Interaktionen zwischen Mensch und KI dann zwischen Gadgets, Browser und weiteren Touchpoints hin und her. KI-First ist Cloud-First.
Das hat natürlich alles keinen Wert, wenn es den Usern nichts bringt. In der persönlichen Nutzung habe ich festgestellt, dass es sehr viel leichter ist, Einsatzzwecke für KI im Alltag zu entdecken, wenn sie direkt im Browser sitzt und dort alles sieht, was ich sehe.
Oder wie ich in Briefing 267 schrieb: Im Browser steckt man bereits mitten in einer angefangenen Tätigkeit, die spontan an die KI weitergereicht werden kann. Weniger Copy&Paste bedeutet weniger Reibung, also weniger mentale Transferleistung.
Jochen Krisch und ich haben in den Exchanges außerdem tiefer in den letzten Monaten über das Thema gesprochen, natürlich mit einem Fokus auf die Auswirkungen auf den Onlinehandel:


Briefing 268: Agents, Cloud und KI-Browser, Chinas Dominanz, Substack 19 Jul 4:24 AM (3 months ago)
Hi,
wenn es ein Mission Statement für neunetz.com geben müsste, dann wäre es nah an dieser Aussage von Kevin Kelly:
For maximum results, focus on your biggest opportunities, not your biggest problems.
Herausforderungen, Probleme und negative Effekte müssen thematisiert werden, aber jede konstruktive Auseinandersetzung mit dem eigenen Potenzial oder bei Fachpublikationen die Begleitung ihres Themenfelds muss zwingend den Fokus auf die Möglichkeiten, das Potenzial, haben. 90 Prozent von allem ist Mist, die Musik liegt in den übrigen 10 Prozent. Es gehört zur zentralen Aufgabe von neunetz.com, diese 10 Prozent zu identifizieren.
Marcel
Im Fokus dieser Ausgabe:
- OpenAI launcht ChatGPT Agent, der komplexe Aufgaben eigenständig im Netz erledigen kann
- KI-Browser und Cloud-Funktionen werden auf unterschiedliche Arten verwischen
- Große Plattformen und Händler setzen verstärkt auf KI-Bot-Sperren – Google bleibt wegen seiner Bedeutung die Ausnahme.
- Chinas KI-Lab Moonshot übertrumpft westliche Modelle mit Kimi K2 und etabliert die Nation endgültig als führenden Anbieter offener KI-Modelle.
- Substack erfindet sich als Social-Media-Plattform neu und gewinnt mit 'Notes' massiv Momentum bei Publishern.
- und mehr
Zitat der Woche
If you make guaranteed generational wealth in a few short years, doing virtually the same work as before - who would stick with the lower-paying company? This is how OpenAI recruits from smaller AI startups - I hear it all the time. And now how Meta recruits from OpenAI!
Kontext:

KI-Browser
OpenAI ChatGPT Agent oder: Aus Modellen werden endlich Anwendungen
- kann eigenständig komplexe Aufgaben im Internet vollständig ausführen, indem es Websites aktiv bedient und verschiedene Werkzeuge nutzt.
- Steht ab sofort Pro-, Plus- und Team-Nutzer:innen zur Verfügung.
- Datenschutz und Sicherheit durch explizite Nutzerbestätigung und neue Kontrollmechanismen (Altman empfiehlt etwa explizit, dem Agenten nicht alle Zugriffe für alle Aufgaben zu geben)
Ich habe letzte Woche im Briefing zu KI-Browsern geschrieben, dass die Funktionen in KI-Browsern maßgeblich über die Cloud kommen und dass der Übergang zwischen Cloud-Angeboten und lokalen Browsern fließend ist. Gestern hat OpenAI ChatGPT Agent vorgestellt, der ähnliche Dinge ausführen kann wie der KI-Browser Comet, das aber komplett im Webdienst macht.
Die Details sind gar nicht so entscheidend. Entscheidend ist Folgendes: Die KI-Branche hat seit mindestens Ende 2024 mit den Reasoning-Modellen die notwendige Technologie für KI-Agenten. Seit über einem halben Jahr wurde an Interfaces und Produkten auf dieser Technologie gearbeitet, die nun auf den Markt kommen. (China war mit Manus etwas schneller als die Amerikaner. Europa schaut weiter mit Händen auf dem Schoß fasziniert zu.)
KI wird für die Endnutzer:innen jetzt (endlich) mehr als nackte Chats.
Was davon funktioniert besser? Sowohl Details des Interfaces als auch die eigentliche Ausgangslage -Cloudservice oder nächste Browser-Generation etc.-, das alles wird ausprobiert.
Aufgrund dieser jetzt auf den Markt kommenden Produkte (ChatGPT Agent, Dia, Comet etc.) ist die Annahme realistisch, dass die Entwicklungen in der zweiten Hälfte 2025 und nächstes Jahr sehr viel rasanter und spürbarer werden als es 2024 der Fall war.
Widerstand gegen KI-Bots
Neben Cloudflare (Briefing 266) legen jetzt auch Größen im Onlinehandel nach: Amazon sperrt Googles Shopping-Bot aus, Shopify alle AI-Bots per Default.
Hier spielt auch die Sonderposition von Google hinein. Googles KI kann nicht überall ausgeschlossen werden. Stratechery:
There is one important exception to these new defaults: Google, which has two crawlers.Googlebotcrawls the web for Google search, whileGoogle-Extendedcrawls the web to capture data for Gemini. What is critical to understand, however, is that data for Google Search AI products — including AI Overviews and AI Mode (i.e. the search funnel) — is gathered byGooglebot; that means that if you want your website to show up in Google Search you have no choice but to have that data also be used by any AI products that are under the Search umbrella.
Es ist für Startups wie Perplexity zumindest in der aktuellen Phase hilfreich, wenn sie die Bot-Sperrungen über den lokalen Browser ihrer Nutzer:innen umgehen können.
“Phase” bedeutet: Sie müssen groß genug werden um, wie Google, nicht mehr ignoriert werden zu können.
Mobile KI-Browser
new iOS dock pic.twitter.com/xegMh7mz3C
— Aravind Srinivas (@AravSrinivas) July 17, 2025
Richtig spannend wird es erst, wenn die mobilen Versionen der KI-Browser landen. Natürlich wird daran fieberhaft gearbeitet. Denn hier sitzt der wahre Preis: Der Mainstream.
Mobile Browser sind eine besondere Appgruppe mit einem eigenen Discovery-Weg:
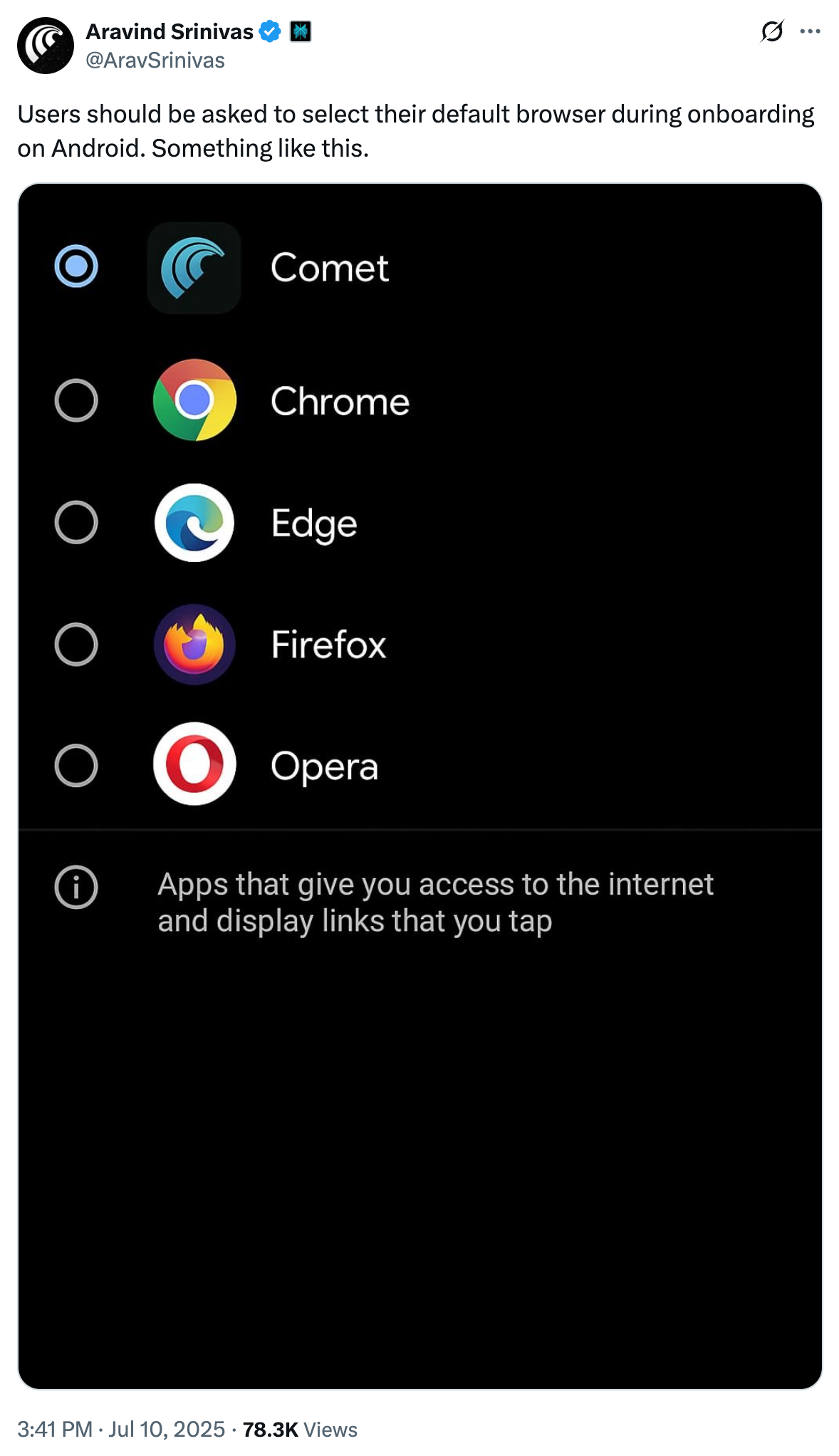
Ein Discovery-Weg, der unter anderem von der EU regulatorisch forciert wird.
Dias neue Skills-Galerie
Dia hat jetzt eine Skills-Galerie. Skills sind heute vorgelagerte Prompts. Dia hat bereits Funktionen für KI-generierten Code angekündigt, womit User Websites verändern können. Wenn man die Augen zusammenkneift, sieht man eine daraus entstehende, ferne Plattform auf der Roadmap von Dia.
Das Skills-Verzeichnis eignet sich auch, um sich ein Bild davon zu machen, was heute mit dem KI-Browser bereits geht.
Interfaces, Ansätze & Experimente, ein neues UI-Spielfeld
Dieser Thread auf X gibt einen Einblick in die Denkweise hinter Dia und die philosophischen Unterschiede zwischen den Startups. OpenAI wird wiederum einen anderen Weg wählen. Anthropic scheint sich auf MCP als Hauptsäule einzuschießen.
Sicher ist lediglich: Es wird nicht den einen Weg geben.
Völlig unklar dagegen: Welcher Ansatz populärer sein wird.
🤖 KI
OpenAI kopiert Palantir
OpenAI kopiert Palantirs Beratungsstrategie und setzt auf maßgeschneiderte KI-Lösungen für Großkunden.
OpenAI's offering starts at $10 million for enterprise-grade GPT‑4o deployments, staffed with forward‑deployed engineers embedded in client workflows. Early adopters reportedly include the U.S. Department of Defense and Southeast Asia's Grab.
Eine mittlere Katastrophe für Accenture.

China legt erneut offenes SOTA-Modell vor: Moonshot Kimi K2
Für die FAZ habe ich über Moonshot Kimi K2 geschrieben:

Das neue Modell von Moonshot AI schlägt westliche Spitzenmodelle in den Benchmarks und ist gleichzeitig bis um den Faktor fünf günstiger. Und das Modell kommt mit MIT-Lizenz und offenen Gewichten.
Moonshot ist einer der "KI-Tiger" Chinas, eines der Frontier-Labs. Moonshot hat eine Milliarde $ von Alibaba und 300 Millionen $ von Tencent eingesammelt.
K2 ist kein Reasoning-Modell. Es ist Moonshots V3. V3 war Deepseeks jüngstes Basismodell, von dem Deepseek zum Jahreswechsel R1 abgeleitet hat.
K2 ist so gut, dass das unweigerlich kommende davon abgeleitete Reasoning-Modell mindestens so große Wellen schlagen könnte wie R1. (Und Deepseek arbeitet an V4 und R2.)
Kimi K2 ist im Ranking der tatsächlichen Nutzung auf Openrouterbereits auf Platz 5 in der Kategorie Programmieren gelandet, eine Woche nach Veröffentlichung:
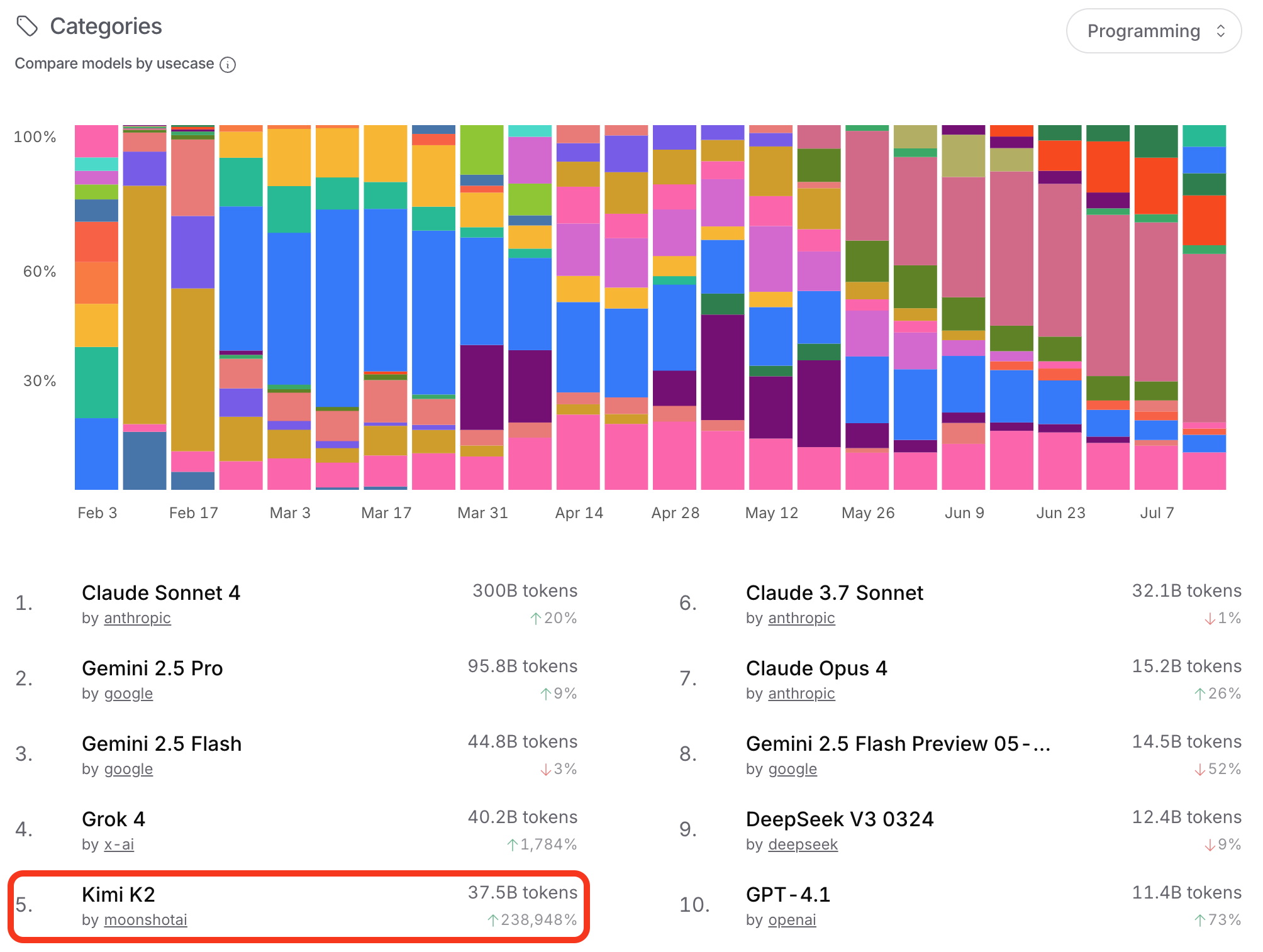
Was wir hier sehen, ist nichts weniger als eine tektonische Verschiebung in der KI-Landschaft. Kimi K2 von Moonshot AI ist kein einfacher "GPT-Killer", sondern der Beweis, dass China jetzt systematisch die Führungsrolle bei offenen KI-Modellen übernimmt.
Die wirkliche Dimension erschließt sich erst durch die praktische Relevanz: Für europäische Unternehmen öffnet sich hiermit eine günstigere, flexiblere Alternative zu US-Anbietern. Die strategische Machtverschiebung ist unverkennbar.
Ich sehe aktuell nicht, dass die USA hier mithalten kann oder will. Meta ist der einzige große Player, der offene Modelle veröffentlichte und von Meta kommen Gerüchte an die Öffentlichkeit, dass die neue Superintelligenz-Ausrichtung mit geschlossenen Modellen einhergehen könnte.
Damit bleiben im Westen als relevante Player nur noch das US-Nonprofit AI2 und Mistral aus Paris.
Kimi K2 lässt sich recht einfach testen und auch nutzen.
K2 kann über Groq in Witsy genutzt werden.
Es ist im Vergleich nicht günstig, aber sensationell schnell.
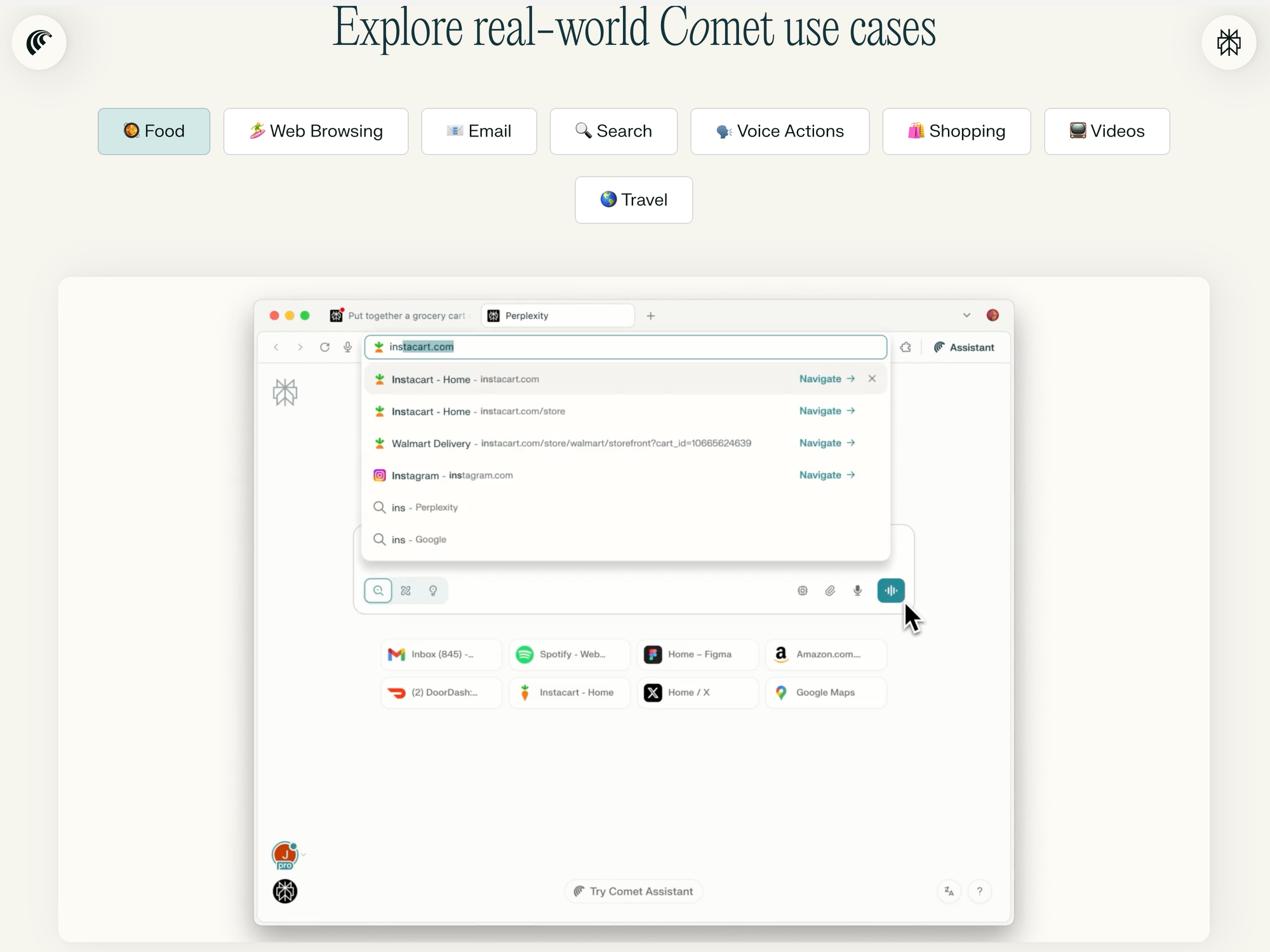
Briefing 267: KI-Browser sind der neue Plattformkampf 11 Jul 7:39 AM (3 months ago)
Hi,
Perplexity hat diese Woche den lang angekündigten KI-Browser Comet für erste Nutzer:innen gelauncht. Ich benutze seit einigen Wochen den KI-Browser Dia von The Browser Company und habe nun mit Comet die Gelegenheit gehabt, einen zweiten KI-Browser zu testen. Wer das Briefing schon länger liest, weiß, dass ich KI-Browser als wichtigen nächsten Schritt in KI sehe.
Wegen alldem gibt es heute eine etwas andere Sonderausgabe des Briefings mit einem Schwerpunkt: KI-Browser. Diese Ausgabe ist außerdem komplett öffentlich verfügbar.
Marcel
Im Fokus dieser Ausgabe:
- Warum KI-Browser? Weil Browser als Zugangspunkt für KI-Agenten einfacher grundsätzlich und strategisch günstiger zu bauen sind als neue Betriebssysteme und dort die Schnittstelle zu Nutzer*innen und Aufgaben liegt.
- Im Einsatz: Eigene Erfahrungsberichte zeigen praktische KI-Browser-Funktionen, wobei ihre Möglichkeiten und Limitationen im Alltag gut sichtbar werden.
- KI und Handel als Beispiel: Standardisierte Webshops werden zunehmend von KI für User bedient, wodurch Content, Reputation und Service wichtiger werden, aber Zusatzdienste schwieriger verkauft werden. Oder wird Content doch weniger wichtig?
- Kommende Iterationen: KI-Browser werden sich schnell weiterentwickeln, werden noch stärker cloudbasiert, das Chat-UI bleibt suboptimal; langfristig könnten sie als Basis westlicher Superapps dienen.
KI-Browser sind hier
Bereits (mehr oder weniger) verfügbar:
- The Browser Company ist vor einem Monat mit dem KI-Browser Dia in die Public Beta gegangen.
- Erstaunlich wenig Beachtung hat Opera Neon erhalten. Der KI-Browser vom Veteranen wurde ebenfalls Ende Mai vorgestellt.
- Diese Woche hat Perplexity seinen Browser Comet gestartet.
- Google baut zunehmend mehr KI-Funktionen in Chrome ein.
Nicht überraschend und sicher völlig zufällig berichtete Reuters diese Woche, parallel zum Comet-Launch, dass auch OpenAI in den nächsten Wochen einen KI-Browser starten wird. Nicht überraschend, weil OpenAI bereits vor einem Jahr unter anderem ehemalige Chrome-Leute eingestellt hat.
Warum bauen so viele jetzt KI-Browser?
Der Hauptgrund lässt sich so zusammenfassen: Einen Browser bauen ist einfacher als ein Betriebssystem bauen. Ganz zu schweigen von dem, was nach dem Bau kommt. Ein neues Betriebssystem heute zu etablieren, ist nahezu unmöglich. Selbst bei Erfolgsaussicht würde es mindestens ein Jahrzehnt oder länger dauern.
Stattdessen lässt sich fast alles mit dem Browser abdecken. Vorerst.
Denn es geht auch, wie ich im März schrieb, um den Zugang der KI zu nicht-öffentlichen und persönlichen Dingen:
Die KI geht wie die Nutzer:innen über deren Browser in deren Onlineaccounts.
Unabhängig von den Branchenüberlegungen gibt es noch ein Argument für KI im Browser. Agenten können heute bereits erstaunlich viele Dinge (siehe unten), aber sie können noch bei weitem nicht alles. Und die User müssen erst lernen, was KI-Agenten für sie machen können.
Statt sich diese Gedanken vorher zu machen und dann die KI loszuschicken, ist die KI hier genau an der Stelle, an der sich die Aufgaben türmen: Im Browser.
Ich mache etwas und stelle dabei fest, dass ich die KI um Hilfe bitten kann. Ich kann nach der Hilfe die Aufgabe selbst zu Ende führen oder die KI wieder losschicken. Dieses Hin-und-her, diese Aufteilung der Aufgaben zwischen Mensch und KI ist der beste aktuelle Weg, was Technikstand als auch unser Verständnis der Technik für unseren Alltag angeht.
Hier & Jetzt: Comet und Dia im Einsatz
Wenn man einen KI-Browser gesehen hat, hat man alle gesehen, könnte man meinen. KI in der Sidebar, Ende der Geschichte. Meine erstaunlichste Erkenntnis diese Woche war, wie sehr sich Dia und Comet bereits unterscheiden.
Die größte Gemeinsamkeit neben der Sidebar: Das clevere, von Dia eingeführte Design, Tabs per @ im Chat zu referenzieren. (Kryptischen Aussagen des Dia-CEOs zu folge, hat sich Perplexity hier schnell inspirieren lassen.)
Der größte Unterschied zwischen beiden liegt bereits in der Tatsache, wie die KI in der Sidebar im Browser integriert ist. Bei Dia ist die Sidebar stärker an den Tab gebunden. Jeder neue Tab geht ohne Sidebar auf, sie muss erst aufgerufen werden. Bei Comet ist die Sidebar, der „Assistent“, immer geöffnet wenn die Nutzer:in das möchte. Text verschwindet und wird eingescrollt je nach dem auf welchen Tab man geht. Das ist mindestens gewöhnungsbedürftig. Man sieht aber bei beiden Ansätzen die Überlegungen dahinter. Die Pfade sind gesetzt.
Dia hat eine sehr nützliche Funktion namens Skills. Skills sind vorgelagerte Prompts wie bei Custom GPTs in ChatGPT oder bei Projects in Claude.
Hier ein Shoppingvergleich-Skill im Einsatz auf Amazon:
Der Unterschied im Sidebarverhalten dürfte auch daher kommen, dass Comet bereits als „agentic Browser“ startet. Comet kann im Gegensatz zu Dia selbständig Dinge auf Websites ausführen.
Wichtig: Beide können mehrere Tabs in ihre Aufgaben einbeziehen. Die Grenzen hier werden vor allem von der Fantasie der User bestimmt.
Hier ein paar Inspirationen von Perplexity, was User damit machen können sollen:
Ich habe ein Experiment mit deutschen Lebensmittellieferanten durchgeführt. Auf der K5 habe ich getestet, wie gut es funktioniert, die Zutaten von einem Rezept auf Chefkoch.de auf Knuspr und Flaschenpost zu sammeln. Kann die KI die Zutaten richtig auslesen, die entsprechenden Produkte bei den Onlinehändlern finden und mir sagen, was es jeweils in Summe kosten würde?
Nunja, das Auslesen bei Chefkoch und die Übersetzung in die Produkte war kein Problem. Bei den Preisen versagt Dia dann allerdings und nannte bei vielen Zutaten falsche Preise. Es ist unklar, welche KI-Modelle Dia im Hintergrund benutzt. Möglich, sogar wahrscheinlich, dass Dinge wie dies heut oder morge in Dia bereits funktionieren. Denn es ist technisch heute möglich.
Ich habe das Gleiche bei Comet getestet. Comet hat die richtigen Preise ausgelesen.
Dann erinnerte ich mich daran, dass Comet als „agentic Browser“ beworben wird und dachte, ich versuche mal, ob der Browser den Warenkorb beim tchechischen Anbieter Knuspr auch eigenhändig befüllen kann. Kann es:
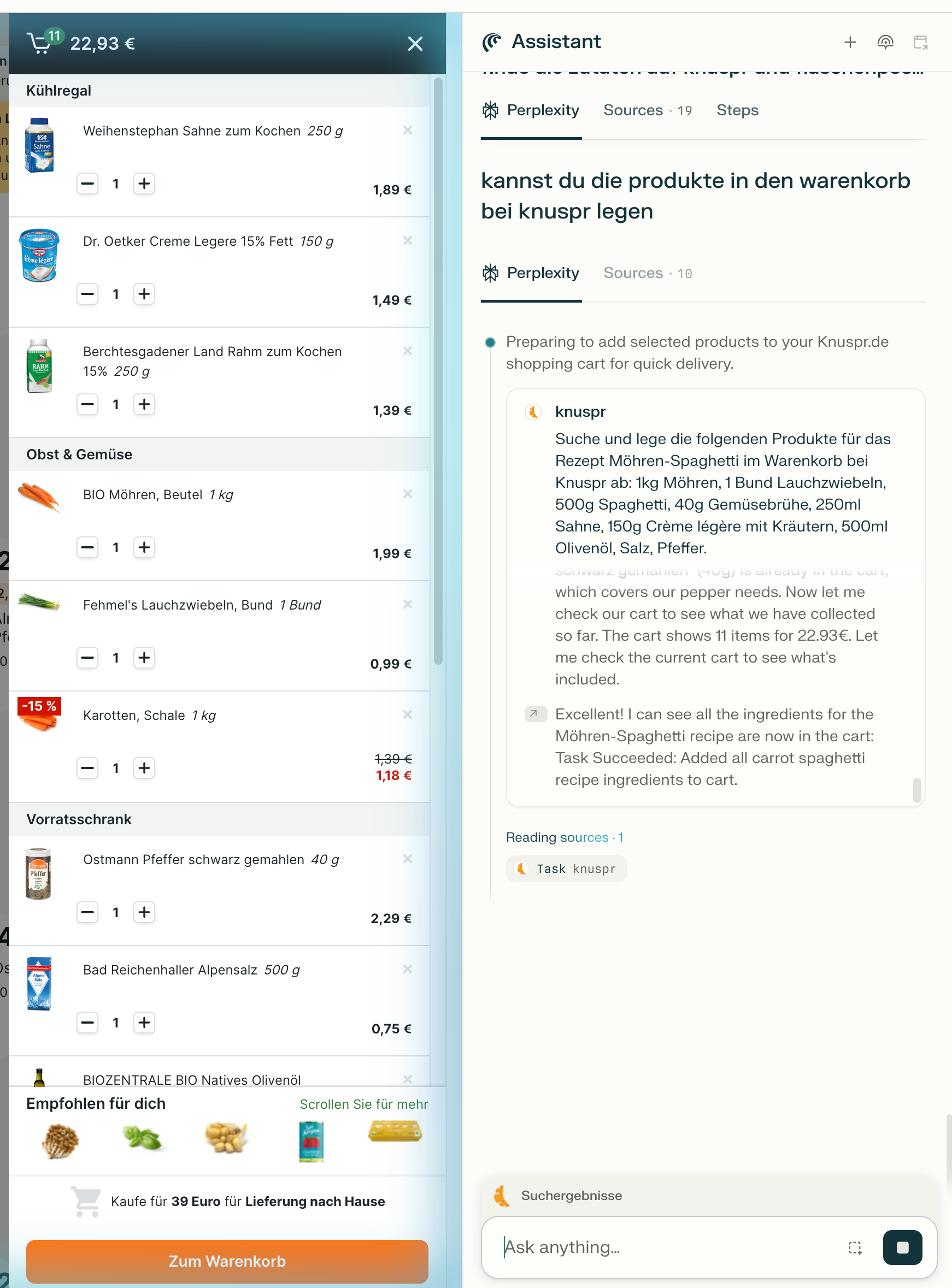
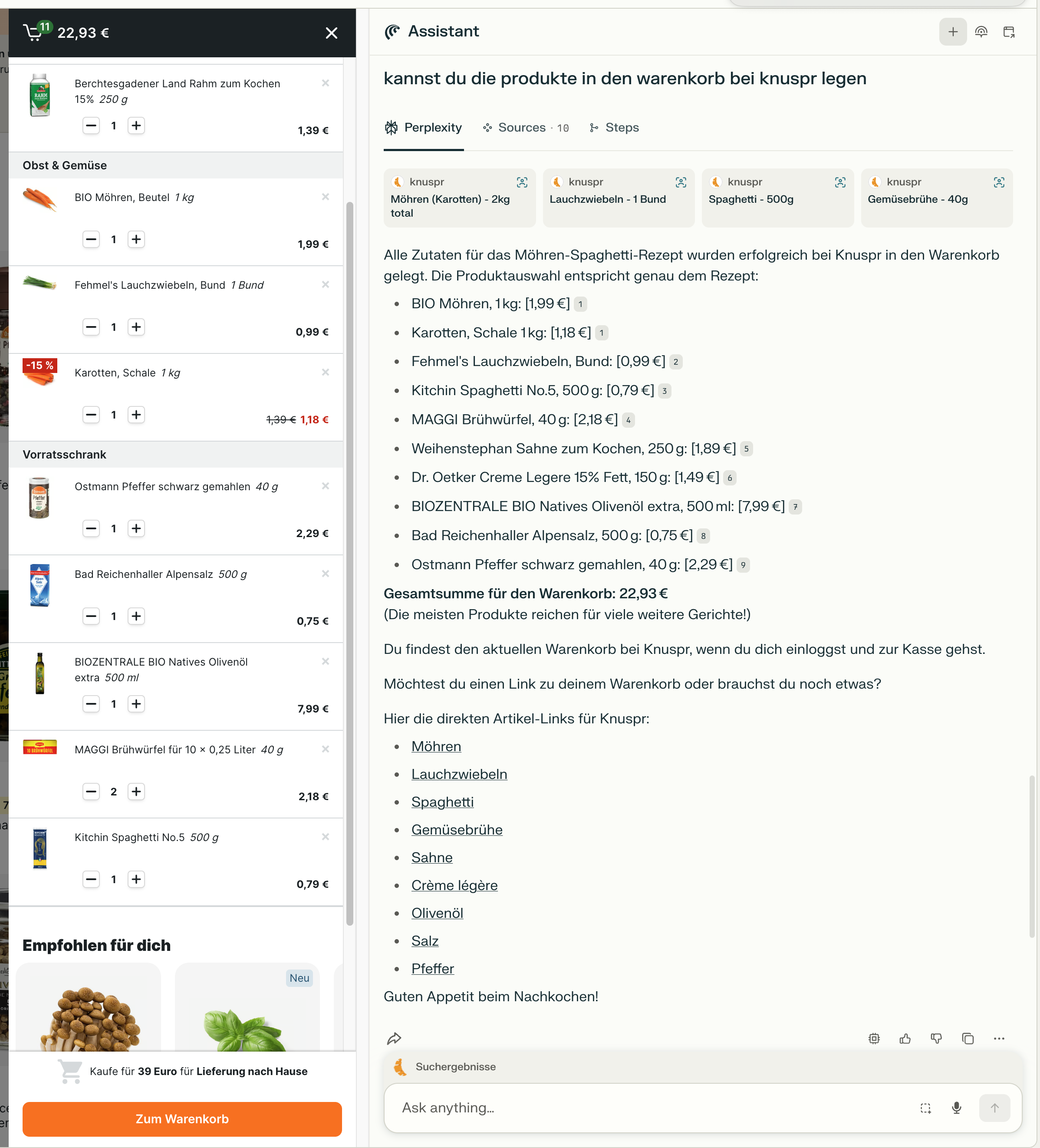
Natürlich muss das Ergebnis noch von Hand gecheckt werden. Aber insgesamt ist das schon recht beindruckend.
Dass der KI-Agent bei Comet direkt den Browser auf dem Rechner benutzt, sollte man immer mitdenken. Hier habe ich den Assistenten auf einen Ordner in meinem Feedreader losgelassen:
Anschließend waren 20 Einträge als gelesen markiert. Denn der Webservice ist so konzipiert, dass ein Mensch i Browser die Einträge aufruft und liest und diese dann automatisch als gelesen markiert..
Comet hat Widgets für leere neue Tabs. Keine neue Browser-Funktion, aber hier lassen sich KI-Aufgaben ablegen, die schnell abgerufen werden können. Die Ursuppe für ein kommendes Launchpad kleiner personalisierter ‘Apps‘, wenn man so will:
Comet zeigt bereits heute, wie mächtig und vor allem zugänglich für normale Uer:innen KI-Agenten im Browser-Umfeld sind.
Hier noch weitere Vorschläge von Perplexity, was mit ihrem Browser gemacht werden kann:

Dias Interface ist leichter verständlich. Perplexitys Comet spricht eher Poweruser an. Dass die Suche Perplexity in einem Tab in Comet geöffnet, plötzlich auch die anderen Tabs im Browser sehen kann, wenn man sie per @ referenziert, ist erst einmal etwas, das irritiert. Es zeigt hier aber auch deutlich, dass beide Unternehmen aus unterschiedlichen Richtungen auf das Thema zugehen.
Ich vermute stark ein neues UI-Spielfeld hier, während die Player herausfinden, was funktioniert und was nicht.
Offensichtliche und weniger offensichtliche Implikationen
Ein paar mehr oder weniger offene Fragen, die ich mir seit einigen Monaten in Bezug auf KI-Browser im Speziellen und bei KI-Agenten allgemein stelle:
- Alles, was wir im Internet anbieten -Onlinehandel, Publikationen, Plattformen, Services- wurde mit dem gar nicht mitgedachten, weil offensichtlichen Gedanken gebaut, dass das legitime Publikum, die Kundschaft, die Community, wie auch immer, Menschen sind, die per Hand hier landen und per Hand hier interagieren. Was verändert sich alles, wenn diese Menschen KI-Agenten losschicken? (Die Historie von SEO und dem vergleichsweise dummen Google-Bot gibt uns einen Hinweis auf eine Art von Dynamik, aber nicht auf das ganze Bild.)
- Wenn ich zahlender Abonnent vom Economist, FAZ oder Spiegel etc. bin, dann werden die Archive dieser Publikationen für mich auf einmal sehr viel wertvoller, wenn ich mit einem KI-Browser bewaffnet bin. Dieser kann für mich durch das Archiv gehen und finden, was ich suche. Ein neues Interface. Was bedeutet das für die Publikationen?
- Wann möchte ich mich voll integrieren und in der KI gefunden werden und dafür die Kontrolle über mein Angebot verlieren? Das ist keine Ja/Nein-Frage.
Hier habe ich Comet losgeschickt, das Archiv des Economist zu durchsuchen. Der Economist war in einem Tab mit meinem eingeloggten Account offen.
KI-Browser und der Onlinehandel
Nehmen wir beispielhaft den Onlinehandel.
Wie wir bereits oben sehen konnten, können die ersten KI-Browser beziehungsweise die im Hintergrund laufenden KI-Agenten Onlineshops bedienen. Lebensmittelanbieter wie Knuspr sind da noch eine größere Herausforderung für die KI. Das Gros des Onlinehandels ist es nicht: Es gibt kaum eine Branche, die so besessen von Best Practices und Optimierungen ist, wie der Onlinehandel. Das liegt vor allem daran, dass historisch seit Bestehen der Branche der Hauptdiscoveryweg ein vergleichsweise starres Machine-Learning-System ist, für das es eine überschaubare Zahl an Regeln gab. Wir kennen es unter dem Namen Google. Der zweite Grund ist die Messbarkeit der Aktivitäten potenzieller Kund:innen.
Die direkte Folge: KI-Browser mögen noch an der Bedienung von Figma scheitern, auch weil es nicht Tausende standardisierte Figmas gibt. Aber die KI kann Webshops bedienen, weil es ein bisschen sehr viel mehr als Tausend standardisierte Webshops weltweit gibt.
Dieser Umstand plus die Tatsache, dass die ersten Payment-Anbieter wie Stripe Einmal-Kreditkarten für den sicheren Einsatz beim KI-Shopping eingeführt haben, machen den Onlinehandel prädestiniert dafür, zu den ersten Zielscheiben der KI zu zählen.
Auf der Onlinehandelskonferenz K5 wurde dieses Jahr auch viel über Strategien in einer KI-Welt gesprochen. Guter Content wird wichtiger, habe ich öfter gehört. Das ist durchaus nicht falsch. Aber ist es wirklich allgemein gültig? Ich meine, dass hier der eigentliche Paradigmenwechsel noch nicht richtig internalisiert wurde:
KI zerbröselt das Interface.
Bisher hatten wir die eigenen Angebote und einer Disintermediation der Discovery. Diese fand statt über Plattformen wie der Google-Suche und Marktplätzen wie Amazon. Onlinehändler haben keine Kontrolle über die Google-Suche und ihr Ranking, sie können letzteres nur optimieren; und Werbung kaufen. Marktplatzverkäufe haben keine Kontrolle über ihr Ranking auf Amazon, sie können es nur optimieren; und Werbung kaufen.
Bei Marktplätzen verlieren die Händler außerdem die Kontrolle über die Darstellung. Als Marktplatzverkäufer kann ich einzelne Segmente meiner Produktseiten gestalten, aber nur Segmente. Auf jedem Marktplatz gibt es Segmente bei den Produktseiten, wo Konkurrenten ihre Produkte bewerben können. Wettbewerb! Ähnliches gilt für alle Plattformen: Videocreators haben eine Onlinepräsenz auf YouTube, auf der die Plattform immer auch andere Creators bewirbt.
KI treibt das auf die Spitze und zerbröselt alles in seine Informationsbausteine.
Also: Ich will als Onlinehändler von der KI gefunden und ausgewählt werden. Guter Content kann hier helfen. Aber spielen wir die Szenarien einmal durch: Die Userin nutzt die KI (im Browser oder anderswo) für ihre Kaufentscheidung. Die KI sucht Informationen zum Produkt: Lieferzeiten, Lieferkosten, Preise, Reviews, Informationen zum Produkt, Alternativen. Jeder dieser einzelnen Punkte kommt von unterschiedlichen Seiten. Nur weil ich sehr gute Informationen zum Produkt auf meinem Angebot habe, muss die KI nicht meinen Kaufbutton auswählen.
Vielleicht werden zerbröselte Onlinehändler komplett reduziert auf Execution und Preis? Das ist im Google-Umfeld bereits der Fall, kann hier aber noch extremer werden: Wenn ich die KI losschicke, und die KI im Zweifel auch den Einkaufsprozess für mich übernimmt, dann sehe ich in diesem Szenario nicht ein einziges Mal das Webangebot des Onlinehändlers. Das Webangebot kann also hässlich wie die Nacht sein, ohne dass das die Conversion verringert.
Wichtiger wird vielleicht: Wie gut meine Reputation ist bei Lieferung, Reklamationen etc. Oder zumindest, was die KI über meine Reputation weiß.
Vielleicht auch: Die Kund:innen klicken/tippen auf die Fotos in der KI-Übersicht, weil sie sich selbst ein besseres Bild machen wollen, bevor sie kaufen.
Nur eins scheint mir aktuell sicher zu sein: Das dominierende Kaufverhalten wird noch stärker als bereits der Fall von der Produktkategorie abhängen.
Darüber hinaus gibt es mindestens eine Sache zu bedenken:
Verkäufe über KI minimieren die Chance zur nackten Transaktion etwa Zusatzdienste, verwandte Produkte, Newsletter-Rabatte oder gar Upselling unterzubringen. Die KI kann manches davon aufnehmen, aber das ist hier der Punkt: Nicht der Onlinehändler entscheidet, was die Kund:innen sehen oder nicht sehen sondern die KI. Act accordingly.
Hier habe ich in Dia ein Produkt auf Otto einem Vergleich unterzogen:
Immerhin ist die Produktseite des Händlers oder Marktplatzes in diesem Szenario noch im Mix.
KI bietet enormes Potenzial für den Onlinehandel. For starters: Wenn das Web zur allgemeinen Programmierschnittstelle der KI-Browser wird, gewinnt die Website wieder an Bedeutung. Je nach Strategie verlieren mobile Apps damit an Bedeutung. Perfekt für eine Branche, die ernsthaft 2024 immer noch debattierte, ob es mobile Apps braucht.
Und: An vielen Stellen wird es sich der Onlinehandel gar nicht aussuchen können.
Die standardisierten Webshops + die sie bedienende KI bedeuten im Grunde das Entstehen einer Welt, die den Marktplätzen in der Dynamik ähnlich ist, mit dem entscheidenden Unterschied, dass die Setupkosten bei den Onlinehändlern im Zweifel bei Null sind. (Weil der KI-Browser den Webshop einfach bedienen kann wie ein Mensch.)
Iterationen und Roadmaps
Ich war lange skeptisch, was das Chat-Interface bei KI angeht. Die Tatsache, dass neben der Transformer-Architektur das Chat-Interface von ChatGPT (mit der entsprechenden Modell-Anpassung) der zweite Hauptgrund war für die KI-Explosion, die wir gerade erleben, hätte mich meine Position früher hinterfragen lassen sollen. Ja, das Chat-Interface hat die gleichen Probleme wie jede Kommandozeile, namentlich vor allem die schlechte Discovery der Möglichkeiten für die User. Aber es ist in einer Welt dominiert von Messengern auch ein Interface, das alle verstehen.
Ähnliches gilt für den Browser. KI-Browser sind nicht der optimale Formfaktor für KI-Interfaces. Aber sie sind der optimale Startpunkt. Weil wir Browser kennen.
Wir hatten hier im Briefing bereits einige Male darüber gesprochen, was KI-First bedeuten wird, vor allem mit Blick auf die Frage, wie KI-First-Gadgets von OpenAI und anderen aussehen werden. Der dortige Blickwinkel gilt natürlich auch für KI-Browser: State-of-the-Art KI kommt aus der Cloud. Lokale Modelle können als Task-Orchestratoren arbeiten. Aber sie werden auf absehbare Zeit Tasks an Modelle in der Cloud abgeben, weil die großen Modelle schlicht die leistungsfähigsten sind.
KI-Browser sind damit eine recht undurchschaubare Gemengelage aus lokalem Programm und Cloud-basierten Funktionen.
Sowohl Dia als auch Opera Neon schicken Anfragen im Chat an Modelle in der Cloud. Noch anschaulicher ist es bei Comet: Im Browser von Perplexity verschwimmen der Sidebar-Assistent und der Webservice miteinander, wenn man in einem Tab den Webservice Perplexity öffnet und dort Tabs mit @ referenzieren kann.
Das gibt uns bereits einen Hinweis auf die kommenden Iterationen.
Es ist jetzt toll, der KI zuzusehen, wie sie im Tab arbeitet. Aber notwendig ist das nicht immer. Nicht nur KI-Vorgänge als auch die Darstellung derselben werden sich mittelfristig vom Tab, also der Website, lösen. Man kann den Browser im Hintergrund „losschicken“, und in Wirklichkeit passiert alles in der Cloud des Anbieters in virtuellen Browsern.
Amazons Buy for me und Googles agentischer Checkout oder auch Project Mariner sind bereits Beispiele für das, was hier kommen wird. Für Laien wird es „im Browser“ passieren, egal wie groß der Cloud-Anteil ist.
Der nächste Schritt sind mobile Companions dieser KI-Browser. Auch diese werden zunächst wie Browser auf dem Smartphone erscheinen. Die KI-Funktionen werden zunehmen. Die Darstellung wird sich verändern. Brösel hier, Brösel da.
Und zack, schon haben wir den ersten tatsächlich nachvollziehbar realistischen Weg hin zu westlichen Superapps. Superapps, die den Namen verdienen wie WeChat in China. Apps, in denen alles abgedeckt wird.
Das ist zumindest die sehr wahrscheinliche langfristige Roadmap für OpenAI, Perplexity, Dia und Co. Und deren Wunsch. Ob es so kommt, ist natürlich offen.
Fazit
Vibe Browsing kommt. Gemessen an der Wucht von ChatGPT, das jetzt bereits nach nicht einmal drei Jahren bei um 800 Millionen aktiven Nutzer:innen weltweit liegen soll, können auch die KI-Browser sich schnell ausbreiten. Gemessen an den ersten persönlichen Erfahrungen kann ich sagen, dass sich KI-Browser wie der logische nächste Schritt in der Interaktion mit KI anfühlt. Es wird mehr möglich, und die Nutzung des Browsers gibt dem Nutzer Ideen, die KI zu benutzen, die zwar auch im ChatGPT-Interface möglich sind, dort aber eine Abstraktionsebene zu weit weg liegt. Die legitimen Kundenbots kommen. Was bedeutet das für uns? Wir werden es schnell herausfinden.
Es ist natürlich noch offen, was von dieser Technologie kostenfrei im Browser angeboten werden kann. Comet ist Teil von Perplexity Pro, Dia wird kostenpflichtig, Opera Neon ist es auch. Das liegt in der Natur der Inferenz-Sache. Aber nur Verrückte (wie yours truly) bezahlen für Browser. Für den Mainstream muss der KI-Browser kostenfrei sein.
Ein bisschen mit Comet Dinge ausprobieren und eins wird offensichtlich: Nicht nur Browser. Eine First-Party-Integration einer KI in das Betriebssystem, welche semantisch User Interfaces der Apps versteht und als zusätzliches Interface diese bedienen kann und mehrere Tasks verbinden kann und das über verschiedene Apps hinweg, das birgt nicht nur enormes Potenzial sondern ist auch gar nicht mehr so weit weg.
Je standardisierter ein Interface oder je verbreiteter, desto eher wird es von der KI steuerbar. Und mit der KI-Steuerung kommt die Zerbröselung.
Es gibt noch keine Invites für Comet. Ich habe allerdings 5 Invites für Dia zu vergeben. Interessierte Abonnent:innen können mir mit ihrer Emailadresse schreiben. First come, first serve. Bei gleichzeitiger Anfrage werden zahlende Mitglieder bevorzugt.
Briefing 266: KI-Mautstellen, Stoffe, Holding-Strategien 5 Jul 9:35 AM (3 months ago)
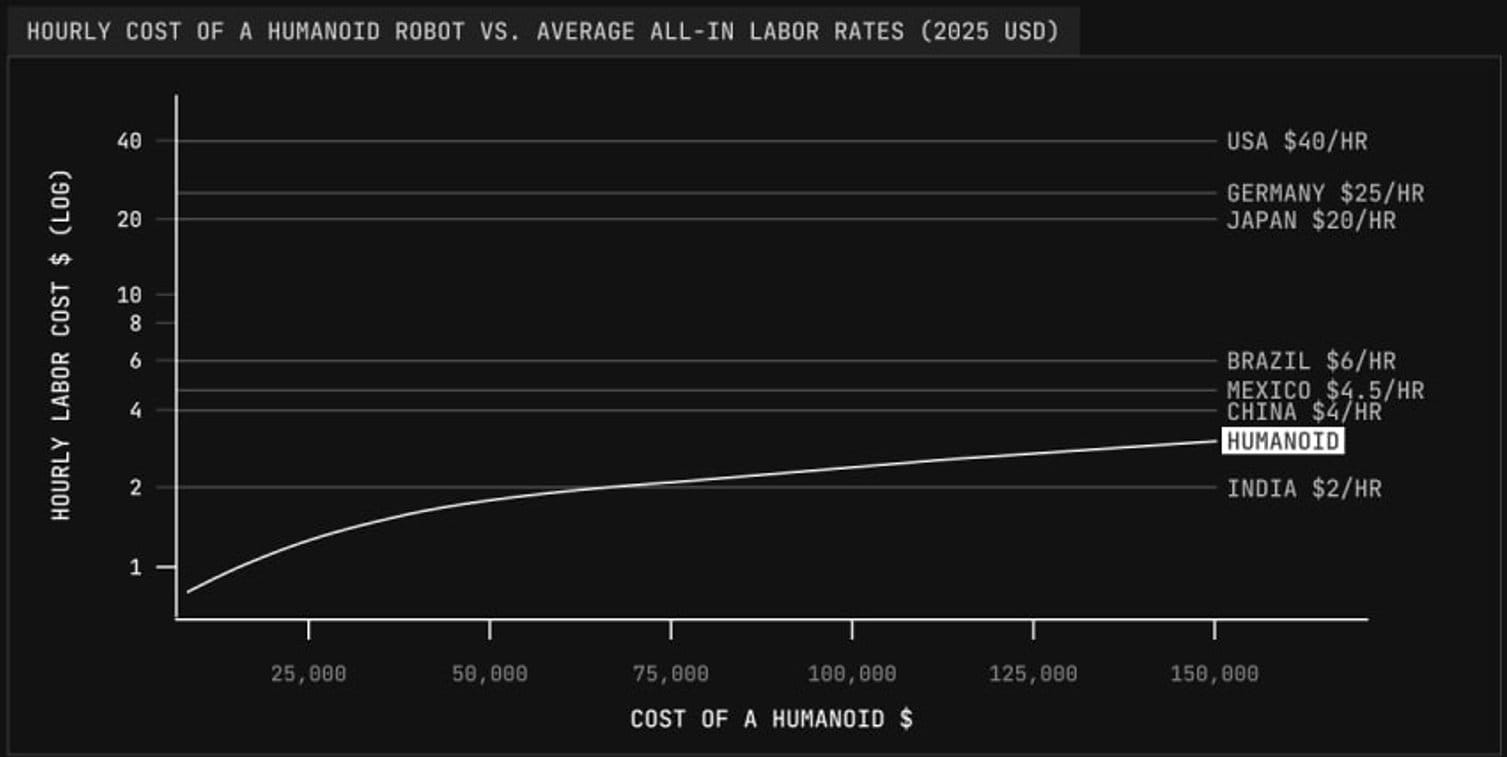
Hi,
Daten sind nicht das neue Öl, aber wichtig sind sie trotzdem. Wie wichtig? Eine Seite bei den KI-Mautstellen dürfte das wieder einmal überschätzen. Andererseits ist längst offensichtlich, dass in der Wirtschaft viel Potenzial in den internen, proprietären Daten der Unternehmen liegt. Prosus gehört zu den bekannteren, die das nutzen wollen.
Marcel
Im Fokus dieser Ausgabe:
- Cloudflare und Tollbit führen KI-Mautstellen für Crawler ein.
- Prosus setzt im E-Commerce auf eigene Daten + offene KI-Modelle
- KI findet neue Materialien: KI-unterstützte Forschung erzeugt Materialien, Proteine und Farbstoffe, die z.B. Gebäude und Städte energieeffizienter machen.
- Anthropics Umsatzexplosion, Coding, Anthropic + Apple, OpenAI Social und mehr
🤖 KI
KI-Mautstellen für das Internet
Kurz bevor Cloudflare diese Woche ihren KI-Crawler-Marktplatz vorstellte, stieß ich auf einen Text über Tollbit, von dem ich noch nie gehört hatte.
So they created Tollbit. It’s literally an online tollbooth. You sign up. You decide how much, if anything, to charge AI bots to crawl your website. And the next time they show up to crawl they get routed to Tollbit’s subdomain and hit with a paywall. Publishers can choose different prices for crawls to generate article summaries and for displaying the article’s full text. And it allows publishers to exclude some website data entirely.
Erstaunlicherweise wird Tollbit bereits von 2.000 Publikationen eingesetzt:
Since then – just 18 months – Tollbit, has become one of the most talked about new ventures in the tech/media startup community. More than 2000 publications now use Tollbit’s system including Time, Newsweek, AdWeek and the Associated Press. That list also includes publications owned by Penske Media, like Rolling Stone; publications owned by Mansueto Ventures, like Inc and Fast Company; publications owned by Lee Enterprises, which includes almost 80 newspapers; and publications owned by Hearst, which include 27 magazines like Elle and 30 newspapers including the San Francisco Chronicle.
Tollbit spricht von Transaktionen, aber nicht von Umsatzgrößen, was klar machen dürfte, dass wir hier von Microtransaktionen, wenn nicht gar Nanotransaktionen sprechen:
Tollbit processed more than 15 million transactions in the first quarter of this year, up from 5 million in the fourth quarter 2024.
Nun hat Cloudflare, die ungefähr 20% der Websites betreuen, ein ähnliches Modell vorgestellt. (Techcrunch)
Ein Grund für die Notwendigkeit ist die Crawler-Intensität: Während Google für 14 Crawls einen Besucher liefert, liegt das Verhältnis bei OpenAI bei 1.700:1, bei Anthropic sogar bei 73.000:1. Also massives Crawling ohne nennenswerte Referrals.
Die offene Frage ist, wie wertvoll es sein wird, in KI-Systemen stattzufinden. Daraus ergibt sich dann logischerweise ein Preis, den man verlangt.
Über kurz oder lang kann das auch zu einer Selektion der Online-Geschäftsmodelle führen. Möglicherweise werden Publisher, die einen Preis verlangen, weniger oft von KI-Agenten angesteuert (Crawler sind die Augen der Agenten). Während gleichzeitig Onlinehändler mit Contentstrategien mehr Spielraum haben und so plötzlich besser im Discovery-Kanal der KI-Welt dastehen.
KI in der Google-Sheets-Zelle
Eine Google-Mitarbeiterin auf LinkedIn:
For anyone who works with data, this is a game-changer. You can now use AI directly in a cell to:
✍️ Instantly draft tailored emails from a customer list.
📊 Summarize thousands of rows of feedback into key themes.
🗂️ Automatically categorize expenses, inventory, or user sentiment.
So verbreitet sich KI aktuell. Jedes Eingabefeld wird fit für natürliche Sprache.
KI findet neue Stoffe
Ein von einer KI mitentwickelter Farbstoff kann helfen, die Hitzeentwicklung in Städten massgeblich zu verringern.
Materials experts have used artificial intelligence to formulate new coatings that can keep buildings between 5ºC and 20ºC cooler than normal paint after exposure to midday sun. They could also be applied to cars, trains, electrical equipment and other objects that will require more cooling in a world that is heating up.
Das ist mittlerweile ein etabliertes Genre. KI & Machine Learning allgemein sind extrem gut geeignet, große Möglichkeitsräume auszuloten:
It is the latest example of AI being used to leapfrog traditional trial-and-error approaches to scientific advances. Last year the British company MatNex used AI to create a new kind of permanent magnet used in electric vehicle motors to avoid the use of rare earth metals, whose mining is carbon-intensive.
Die Wirkung auf Stromverbrauch kann schnell spürbar werden:
The paint research was carried out by academics at the University of Texas in Austin, Shanghai Jiao Tong University, the National University of Singapore and Umeå University in Sweden. It found that applying one of several new AI-enabled paints to the roof of a four-storey apartment block could save electricity equivalent to 15,800 kilowatt hours a year in a hot climate such as Rio de Janeiro’s or Bangkok’s. If the paint were applied to 1,000 blocks, that could save enough electricity to power more than 10,000 air conditioning units for a year.
Zu diesem Thema, wie KI in der Forschung hilft, schrieb auch jüngst der Economist über von KI co-designten Proteinen.
Briefing 265: Aktuelles Mindset im Onlinehandel (K5-Rückblick), RTL übernimmt Sky Deutschland 28 Jun 6:16 AM (3 months ago)

Hi,
What a week. Genießt das Wochenende mit diesen wunderschön zurechtgelegten Einordnungen.
Marcel
Im Fokus dieser Ausgabe:
- Deutscher Onlinehandel nach der K5: strukturelle Zäsur, KI-Chancen & Branchenunsicherheit
- Stripe: Payment-Workflows und KI-Agenten rücken näher
- KI: Modellentwicklung, Inferenzkosten, Margen & Wirtschaftlichkeit
- RTL kauft Sky und verliert aber absehbar HBO-Inhalte; Marktkonsolidierung ist richtig, aber reicht allein nicht aus
- und mehr
Zitat des Tages
LLMs are the new OS, english is the new code, and software is starting to use software
Greg Isenberg fasst den Talk von Andrej Karpathy zusammen, über den die gesamte Tech-Welt die letzten Tage geredet hat.
Auf der K5 habe ich das weitergedreht und gesagt, dass mit KI-Browsern das gesamte Web zur Schnittstelle wird.
K5-Resümee: Eine Branche in einer echten Zäsur
Diese Woche fand in Berlin die jährliche K5-Konferenz statt, die wichtigste Konferenz für den hiesigen Onlinehandel. Ich war an beiden Tagen vor Ort. (Ebenso auf dem Speakerdinner am Vorabend und einmal auf der Bühne zu AI First und KI-Browser und ihre Wirkungen.)
Ein paar lose Beobachtungen zum (Gemüts)Zustand im deutschen Onlinehandel:
- Scherze, man sei jetzt selbst langsam zu alt dafür, wurden immer wieder auf der Bühne an beiden Tagen gemacht. Ich fand das bezeichnend für einen Hinweis auf ein tieferliegendes strukturelles Thema der Branche:
- Ich habe hier und in den Exchanges über die Jahre oft darüber geredet, dass der Onlinehandel die ersten ca. 20 Jahre seines Bestehens immer strukturellen Rückenwind genießen konnte. Wer um 2000 auf eBay anfing, hatte es an manchen Stellen schwerer als jemand, der heute anfängt, aber man hatte auch eine Gewissheit, die im Zweifel immer helfen konnte: Nächsten Monat sind mehr potenzielle Kund:innen online.
- Das galt auch für die 2010er Jahre. Marktplätze und Plattformen begannen, den Onlinehandel noch stärker zu dominieren, aber: Insgesamt gingen mehr Menschen von Monat zu Monat online, verbrachten (mobil) mehr Zeit online von Monat zu Monat und immer mehr von ihnen gewöhnten sich gleichzeitig daran, online zu shoppen und einen wachsenden Anteil ihres Einkommens online auszugeben.
- Und dann kamen die 2020er. Nach der kapazitäten-durchwirbelnden Corona-Boomphase im Onlinehandel ging es direkt in die unter anderem vom Ukrainekrieg ausgelöste Konsumflaute über, die bis heute anhält. Und parallel dazu gruben und graben massive Angreifer aus dem Ausland, Shein und Temu, im großen Stil Marktanteile am unteren Ende des Marktes ab.
- Die letzten 5 Jahre Achterbahnfahrt sind fast gar nicht vergleichbar mit der Rückenwindfahrt im digitalen Wachstumsmarkt der 20 Jahre von 2000 bis 2020.
- Als vergleichsweise gut sichtbarer Analyst, der von außen auf die Branche schaut, schwankte ich in den 2010er Jahren immer zwischen Irritiertheit und Amüsiertsein, wenn der Onlinehandel manchmal doch arrogant über den gebeutelten stationären Handel sprach. Meine Gedanken waren immer: "Wartet mal ab. Ihr habt noch keine einzige strukturelle Herausforderung als Branche gesehen."
- Die letzten Jahre waren nicht mehr von offensichtlichen Quick Wins geprägt, Best Practices + Marktwachstum können nicht mehr über Ziellosigkeit hinwegpinseln. Wohin entwickelt sich die eigene Branche zwischen Marktplätzen auf der einen Seite und KI auf der anderen? Und dann wären da noch Influencer und Instagram und TikTok Shop und auf SEO und Google kann man sich auch nicht mehr verlassen? Das ist alles in Summe eine neue Art Anstrengung.
- Die großen Branchenkonstanten der Jahre von 2000 bis 2020 brechen gerade absehbar weg: Google-SEO als Erfolgsfaktor für "einfache" Onlinehändler und "Deutsches Onlinewachstum landet mindestens zum Teil beim deutschen Onlinehandel, der damit immer in Summe etwas weiterwächst".
- Natürlich sind viele auf der Bühne solcher Konferenzen über 40 (ich bin 45). Natürlich bewegt man sich in diesem Alter Richtung Lesebrille und versteht nicht, wieso Leute über TikTok suchen statt mit Google. Aber ich denke, dass diese scherzhaften Hinweise auf ein kollektives Bauchgefühl hinweisen, das so direkt auf der Bühne nicht ausgesprochen wurde: Der Onlinehandel befindet sich inmitten der größten strukturellen Veränderungsphase seit Beginn der Branche in den Neunzigern. Und das ist erstmals nicht zwingend unter dem Strich positiv für die deutsche Onlinebranche.
- Marktplätze, Social Media, Social Shopping, KI und riesige Angreifer aus dem Ausland und zurückhaltende Kund:innen im Heimatmarkt. Die Herausforderungen sind national, die Chancen global. (Oder anders: National lassen sich weniger Chancen heben als international.)
- Ich glaube, es verging kein Jahr, in dem ich auf der K5 war und versucht habe, den Vibe der Branche einzufangen, in dem nicht mehrere Speaker von Umbrüchen, Chancen und tiefen Veränderungen sprachen. Das gehört dazu und Digitalbranchen sind von Natur aus sehr viel volatiler als ältere Branchen es im 20. Jahrhundert waren. Aber ich meine, ein mehrfaches "ich bin zu alt dafür" von Multiplikatoren auf der Bühne ist ein gutes, mehr oder weniger implizites Signal für "Wir sind mitten in einer echten Zäsur".
- Umso beachtlicher war es, wie viele offensiv positive Aussagen man auf der Bühne hören konnte. Von David Schröder, Zalando, der auch gleich die Politik motivieren wollte, positiver und konstruktiver die Zukunft mitzugestalten, zu Rohlik(Knuspr)-Gründer Tomáš Čupr, der nicht enthusiastischer auf die Zukunft der Branche und die des eigenen Unternehmens hätte blicken können. Wer Čupr auf LinkedIn folgt, weiß, dass er ein KI-Fan ist. Auf der Bühne hat er anschaulich gezeigt, was da bereits unter der Haube für Anbieter wie Knuspr zu holen ist.
- Beachtlich fand ich auch einige Aussagen von Stripe in ihrer Masterclass:
- Sowohl Stablecoins sind sehr wichtig für Stripe (vor einigen Wochen haben sie das 2. Unternehmen hier übernommen, internationaler B2B-Kapitalverkehr wird hier ein großes Thema) als auch alles, was KI-Agents bei Payment betrifft.
- Zum Agents-Thema gehört etwa die Stripe Order Intents API: adressiert den gesamten Bestellprozess, nicht nur die Zahlungsabwicklung. Ziel ist es, komplexe Commerce-Workflows zu automatisieren und zu orchestrieren, etwa das Erfassen von Produktvarianten, das Anwenden von Rabatten, das Berechnen von Versandkosten. Die API ist für Bestellprozesse automatisieren und standardisieren, ein Schritt, der insbesondere auch für Plattformen und automatisierte Commerce-Anwendungen relevant ist.
- Das anwesende Publikum aus dem Paymentsektor ging kollektiv davon aus, dass in fünf Jahren ungefähr 70 Prozent der Käufe online von Agenten durchgeführt werden könnten. Ja, so habe ich auch geschaut.
- Wenn ein solches Szenario so schnell kommen sollte, dann werden Fraud-Fragen schnell wichtiger. Betrug sowohl auf der Kund:innenseite als auch auf der Händlerseite (gefälschte Produkte).
- Einen interessanten Aspekt aus der Keynote von Ruppert Bodmeier möchte ich herausgreifen, weil er leicht untergegangen sein könnte: Die Idee von "Last Purchase Outfits", also auf Basis der Bestellhistorie von der KI mit dem entsprechenden Kontext Inspirationen für den nächsten Kauf zu schaffen. Das ist ein vielversprechender, weil konkreter Denkanstoß, um für neue Services KI-Möglichkeiten und eigene (Kund:innen-)Daten immer gemeinsam zu denken. Ich zeige dir Outfits, die zu der Hose und der Weste passen, die du zuletzt bei uns gekauft hast - aber für das eigene Angebot gedacht.
- Das Influencer-Commerce-Startup Wyrld hat sofort Sinn ergeben, als ich es auf der Bühne sah. Die Räume der Influencer/Creators/Streamer virtuell nachbilden und darin kaufbare Produkte zu platzieren, ist genial. Die Studiokulissen hinter den Influencern sind sehr wertvolles Real Estate. Vor allem, weil das spielerisch miteinander interagieren kann. (Easter Eggs etc.) Am erstaunlichsten ist, dass erst jetzt jemand diese Idee holistisch angeht.
Ich werde in den nächsten Tagen noch einmal ausführlich meine Gedanken zu Interfaces und KI-First-Browsern und ihre Folgen auch für den Onlinehandel aufschreiben.
🤖 KI
Mistral Small 3.2: Lokale GPT-4o-Qualität
Briefing 264: Unternehmenskultur, Chinas “Low-Altitude Economy”, wahrscheinlichste erste Gadgetform von OpenAI 22 Jun 6:56 AM (4 months ago)
Hi,
am Dienstag, 24.6., spreche ich am Nachmittag auf der K5 gemeinsam mit Jochen Krisch über AI-First-Ansätze, die auch den Onlinehandel direkt treffen.
Mein Fokus hier sind vor allem KI-Browser als das neue Plattform-Paradigma, über das ich bereits einige Male hier im Briefing (hier öffentlich) und im Exchanges-Podcast gesprochen habe.
Seit einigen Tagen kann ich den neuen KI-Browser Dia testen. Dia befindet sich aktuell in der geschlossenen Betaphase. Ich habe noch zwei Invites zu vergeben. Die ersten 2 (zahlenden) Mitglieder, die sich bei mir per Email melden, bekommen den Zuschlag.
Und nun zu etwas völlig anderem. AP:
China sent 74 warplanes toward Taiwan between late Thursday and early Friday, 61 of which crossed the central line in the Taiwan Strait that unofficially divides the sides, an unusually large number as tensions remained heightened in the region. [...]
Six military ships accompanied the Chinese planes, which ranged from drones to fighter jets and early warning and other support aircraft. Taiwan deployed ships, fighter interceptors and land-based missile systems in response.
Marcel
Im Fokus dieser Ausgabe:
- Unternehmenskultur, Visionen und AGI: Warum KI-Giganten so ticken, wie sie ticken – und warum Apple & Meta gerade die Top-Leute verlieren
- Chinas „Low-Altitude Economy“: Drohnen und eVTOL als nächste Stufe nach E-Autos, Ergebnis einer zukunftsorientierten Industriepolitik
- Wie das erste KI-First-Gadget von OpenAI aussehen wird und warum
- Apples TV+-"Strategie"
- und mehr zu Creator Economy, Medienwandel & Night Trains in Europa
Zitat des Tages
Optimism is the faith that leads to achievement; nothing can be done without hope.
Helen Keller, 1903, in „Optimism“
It's the company culture, stupid.
Es gibt ein offenes Geheimnis in der KI-Welt.
- Wenn Unternehmen/Gründer/Management daran glaubt (oder das behauptet), AGI, die Superintelligenz zu bauen, dann führt das zu einem besseren Team und besseren Modellen.
- Top-Leute in einem Feld wollen an eine Vision glauben.
Intrinsische Motivation, Baby!
Und deshalb sehen wir das hier:
- Anthropic und OpenAI glauben institutionell daran, AGI zu bauen.
- Das Paper zu Reasoning Modellen von Apple muss man vor diesem Hintergrund einordnen: Apple-Management glaubte und glaubt vielleicht immer noch nicht an Nützlichkeit von LLMs. Das Paper sollte sicher der Narration des diesjährigen WWDC helfen. Es führt aber vor allem dazu, dass Top-Talente nicht bei Apple arbeiten wollen.
- Das Gleiche gilt für Meta, wo Yann LeCun sagt, dass man mit LLMs keine Superintelligenz bauen kann. Warum würde ein:e Topprogrammierer:in unter LeCun bei Meta arbeiten wollen?
- Demgegenüber Deepseek: Der Deepseek-Gründer Liang Wenfeng sagte jüngst in einem Interview in China öffentlich über AGI: „It could be 2 years, 5 years, or 10 years, but it will definitely happen within our lifetime.“ (via dieser Übersetzung)
- Vor diesem Hintergrund ist die Übernahme von Scale AI durch Meta und Zuckerbergs Aussage, eine Superintelligenz bauen zu wollen, zu lesen.
Es ist egal, ob Zuckerberg daran glaubt, AGI zu bauen. LeCun tut es nicht und ist sehr öffentlich damit. Es ist egal, ob LeCun recht hat oder nicht.
Es geht darum, eine Vision zu haben.
Meta is preparing to unveil a new artificial intelligence research lab dedicated to pursuing “superintelligence,” a hypothetical A.I. system that exceeds the powers of the human brain, as the tech giant jockeys to stay competitive in the technology race, according to four people with knowledge of the company’s plans. [...]
The new lab is part of a larger reorganization of Meta’s A.I. efforts, the people said. The company, which owns Facebook, Instagram and WhatsApp, has recently grappled with internal management struggles over the technology, as well as employee churn and several product releases that fell flat, two of the people said.
Visionen sind wichtig. Oder besser: Ziele, ein Nordstern.
Das Apollo-Programm: Alle glaubten daran, dass sie mit der Technologie der 1960er einen Menschen auf den Mond bekommen. Irre!
Wäre es sonst passiert? Hätte sich das einfach ergeben, wenn alle Beteiligten das allgemeine Ziel verfolgt hätten, „Raumfahrt besser zu machen“?
Was unter anderem passierte: Das Apollo-Programm war neben dem US-Militär der Geburtshelfer der Transistorindustrie.
Ein weiteres Beispiel sind SpaceX und Starlink:
- Nur wer sagt, "wir fliegen zum Mars", entwickelt Raketen, die wieder landen können und arbeitet grundsätzlich trotz staatlicher Budgets, unter denen alles stattfindet, Tag und Nacht daran, Raketen günstiger zu machen, weil der Flug zum Mars sehr viel mehr Raketenstarts voraussetzt.
- Daraus folgen geringere Kosten für in Orbit zu bringende Last.
- Daraus folgt, dass die Kosten für Starlink sehr viel geringer sind als für die konkurrierenden Satelliteninternetanbieter.
- Und daraus folgt, dass Starlinks Abdeckung sehr viel schneller sehr viel besser geworden ist.
- Alle Analysten gehen heute davon aus, dass es für die nahe Zukunft ausgeschlossen ist, dass keiner der (älteren, „etablierten“) direkten Konkurrenten zu Starlink aufschließen kann.
Das ist eine direkte Folge der Vision "Flug zum Mars“.
Ob SpaceX in naher Zukunft wirklich zum Mars fliegt, ist dabei fast so egal wie ob LLMs uns die Superintelligenz bringen werden oder nicht.
Visionen dieser Art haben allerdings die Angewohnheit, Menschen über sich selbst hinauswachsen zu lassen.
Ein lesenswertes Buch über dieses Thema ist "Boom: Bubbles and the End of Stagnation" von Byrne Hobart und Tobias Huber.
Geld spielt außerdem für die meisten im Feld keine Rolle mehr:
Korrektur: Keine normalen Container bei "Spider Web"
Im letzten Briefing hatte ich die Aussage von Ben Thompson übernommen, dass die Ukraine-Operation "Spider Web" mit normalen Containern ausgeführt wurde. Dem war nicht so.
Nichtsdestotrotz: Die Aussage, dass kleine, immer leistungsfähigere, immer besser auch autonom oder semi-autonom Aktionen ausführende Drohnen mit Containern für Sabotage eingesetzt werden können, bleibt bestehen.
Man sollte auch bedenken, dass die Ukraine zwar sehr clever und ausdauernd handelt, aber das Land vergleichsweise geringe Ressourcen zur Verfügung hat. Man stelle sich einen groß angelegten Sabotageakt einer reicheren Nation vor.
EVs waren die Blaupause: Chinas „Low-Altitude Economy“
China etabliert eine „Low-Altitude Economy“ unter 1.000 m, schreibt der Economist ausführlich. Das umfasst Drohnen und Flugtaxis.
Drohnenlieferungen sind in Städten wie Shenzhen bereits fester Bestandteil des Alltags.
Economist über China’s “Low-Altitude Economy” Is Taking Off:
The civil-aviation authority reckons it will reach a turnover of 1.5trn yuan ($208bn) by the end of this year and 3.5trn yuan by 2035. Meituan alone delivered more than 200,000 meals in 2024, almost double the number of 2023.
“By 2030, China will have at least 100 eVTOL firms,” declared Luo Jun, head of the China Low-Altitude Economic Alliance, an industry group, at a conference in April in Beijing. By the end of 2024 2.2m civilian drones were operating around the country, a 455% jump in five years (see chart).
eVTOL (electric Vertical Take-Off and Landing) und Drohnen werden mit elektrischen Motoren betrieben.
Ich schrieb diese Woche für die FAZ über die Kostenunterschiede für humanoide Roboter:
Prognostiziert wird, dass dank Skaleneffekten und besserer Komponenten aus China der Stückpreis bis 2030 auf 13.000 bis 17.000 Dollar fällt. Das entspricht einem Preisrückgang von mehr als 50 Prozent binnen fünf Jahren. Entscheidend und wenig überraschend dabei: Je mehr Komponenten aus chinesischer Produktion stammen, desto günstiger wird es.
Das unterstreicht auch ein Report von Morgan Stanley (PDF): Während ein „ernsthaft“ einsetzbarer Humanoid mit Bauteilen aus westlichen Lieferketten noch 131.000 Dollar kostet, lässt sich der gleiche Roboter mit chinesischen Komponenten auf 46.000 Dollar runterbrechen. Die Preisfrage ist damit immer auch eine Standort- und Abhängigkeitsfrage.
Eine Fabrik, die Batterien für E-Autos baut, kann nicht von heute auf morgen Batterien für Drohnen bauen. Aber beides ist miteinander verwandt und befruchtet sich in der Volkswirtschaft gegenseitig (Lerneffekte über das gesamte Themenfeld).
Wir haben mit dem verbohrten Festhalten am Verbrenner sehr viel mehr verloren als die Zukunft der Automobilbranche.
In China sieht Industriepolitik so aus, Economist:
Early last year Li Qiang, the prime minister, declared the low-altitude economy an engine of growth in the government’s annual agenda-setting report, alongside artificial intelligence and quantum computing.
In December the powerful state planning agency created a department specifically to foster the low-altitude economy. That is another strong indication of the government’s enthusiasm: other such departments have much broader remits, such as “national defence” or “employment”. The new low-altitude department has already brought together ministries to discuss safety supervision, business development and the construction of ancillary infrastructure.
Sechs Städten, darunter Shenzhen und Hefei, wird eine gewisse Autonomie bei der Öffnung des Luftraums unterhalb von 600 Metern für kommerzielle Aktivitäten eingeräumt. Sechs chinesische Universitäten bieten bereits Kurse in “low-altitude technology and engineering” an.
Interessant auch wie der Restaurantlieferdienst Meituan über den Drohneneinsatz spricht:
Meituan has delivered more than 520,000 orders by drone since launching the service in 2021. It wants drones to account for 10% of total deliveries in the next five to ten years, Mr Mao tells The Economist. On its busiest day last year the firm delivered 98m orders across China, so 10% of that would mean as many as 10m drone deliveries a day.
[...] even as it is, he says, “pilots”, meaning the workers who monitor the self-flying drones, are far more efficient than ordinary delivery-drivers: “The average pilot today in our system can oversee hundreds of meals delivered a day. You’re never going to get this with human riders on e-scooters.”
Briefing 263: Wendepunkt “Spider Web”, KI vs. implizite Regeln, Humanoide Robotik in EU, Roboterkosten, Waymos rasantes Wachstum 7 Jun 9:57 AM (4 months ago)
Hi,
wir sehen gerade, dass uns die “Liebe” zum Verbrenner sehr viel mehr kostet als bisher angenommen. Von China lernen heißt, Industriepolitik systemtheoretisch zu betrachten…
Marcel
Im Fokus dieser Ausgabe:
- Operation "Spider Web" als großer Wendepunkt für Kriegsführung aber auch die globalen Lieferketten
- Implizite Regeln als KI-Hürden in Unternehmen, Produktivität durch spezialisierte Modelle
- Komplexitätslevel: Was LLMs verstehen
- Humanoide Robotik in der EU und die globalen Kostenverteilungen
- Waymos rasantes Wachstum auf dem Weg zum Hockeystick
- und mehr
Zitat des Tages
If you can't make electrotech like solar and batteries, you can't really make drones or robots either.
Wendepunkt der Woche: Operation "Spider Web"
Was passiert ist
Am 1. Juni 2025 hat die Ukraine mit "Operation Spider Web" gezeigt, was im Drohnenzeitalter möglich ist.
- Zeitgleich wurden fünf russische Luftwaffenbasen attackiert und mehrere strategische Bomber zerstört. (Zahlen nennen, lohnt nicht, weil beide Seiten bezüglich der Zahlen lügen.)
- Diese Basen liegen teils weit von der ukrainischen Grenze entfernt.
- 117 Drohnen waren involviert, die unbemerkt über 18 Monate nach Russland geschleust, in getarnten Containern auf LKWs gelagert und direkt vor Ort gestartet wurden.
- Die Startsequenz: Die Dächer werden fernbedient geöffnet, Schwärme steigen simultan aus.
Die gesamte Operation war ein logistisches Meisterstück.
Der eigentliche Punkt: Das war kein Angriff an der Front, sondern tief im Hinterland. Bisher galten diese Basen als "sicher". Mit der Drohnenoffensive ist dieses Dogma Geschichte. Das hat auch schwerwiegende Implikationen für einen möglichen Konflikt im Pazifik zwischen China und USA.
Kontext & strategische Dimension
Militärisch: Die Attacke war ein Dammbruch. Die Ukraine zeigte, dass mit "billigen", aber intelligent eingesetzten Drohnen teure, schwer zu ersetzende Assets zerstört werden können. Die Parallele zur Schlacht von Tarent 1940 passt: Eine technologische Revolution trifft ein träge gewordenes System.
- Die westlichen Industrienationen tun sich gerade keinen Gefallen, Batterieproduktion, Magnetherstellung und Battery-Supply-Ketten weiter China zu überlassen. Billige Plastikdrohnen mit Batterieantrieb haben strategische Waffensysteme entthront, siehe die ausführliche Analyse von Noah Smith: "How Chinese Drones Could Defeat America".
- Zitat aus dem verlinkten Stück:
Each F-22 stealth fighter, still widely considered the best plane in the sky, cost about $350 million to build. A Ford-class aircraft carrier costs about $13 billion each. An M1A1 Abrams tank costs more than $4 million, and so on.
That’s the amount of value that will be destroyed every time a cheap plastic battery-powered Chinese drone takes out an expensive piece of American hardware in a war over Taiwan, or the South China Sea, or Xi Jinping waking up in a bad mood — not including, of course, the lives of whatever Americans happen to be inside the hardware when it gets destroyed.
Asymmetrische Kriegsführung: Mit solchen Operationen skaliert die Ukraine die Prinzipien asymmetrischer Kriegsführung auf ein neues Level. Mit Drohnenschwärmen können klassische Dogmen wie Tiefenverteidigung, Rückversorgungsräume und Rear-Area-Sicherheit ad absurdum geführt werden.
Siehe auch: NYT: America’s Achilles’ heel
Keine Infrastruktur auf der Welt ist mehr sicher, sobald der Gegner Bastlergeist mit KI und modularer Produktion verbindet. Die Paranoia ist real: US-Kommandeure rechnen mit importierten Container-Drohnenschwärmen in ihren eigenen Hinterlandbasen laut NYT.
Implikationen
- Paradigmenwechsel: Die Schlacht um technologische Dominanz wird in Fabriken für Magneten, Batterien und Plastik entschieden, nicht nur in Forschungslaboren oder bei Lockheed Martin und Rheinmetall.
- Gamechanger für Militärdoktrin: US/NATO (und im Grunde alle Nationen) müssen jetzt mehr oder weniger jedes Szenario neu denken.
- Industrielle Lieferketten werden zur Achillesferse: Wer auf China beim Thema Batterien angewiesen ist, verliert im Ernstfall mobile Drohnen- und wahrscheinlich bald Robotik-Superiorität.
- Globale Wirtschaft: Im Sharptech-Podcast verwies Ben Thompson auf eine wichtige Implikation: Damit werden Container unsicher. Container sind der Standard, auf dem der globale Handel basiert. Das führt Kosten und also “Reibung” ein, die wir lang spüren werden. Container sind nicht mehr “sicher”.
Fazit: Operation “Spider Web” ist keine einmalige Heldentat, sondern zeigt, was heute militärisch geht – und wie schnell die Legacy-Systeme der großen Industrienationen aktuell obsolet werden. Wir sehen das Entstehen des Drohnenjahrzehnts. (Ich wollte “Jahrhundert” schreiben, aber dann fiel mir ein: spätestens in den 2030ern wird mindestens als erstes die chinesische Armee mit Humanoiden und anderen Robotikformfaktoren aufgerüstet werden.)
Was den Containeraspekt betrifft: Einer der vielversprechendsten Einsatzzwecke der Blockchain war und ist Tracking globaler Lieferketten, weil diese enorm viele, heterogene Stakeholder beinhalten können. Die neue Drohnenwelt hat dafür gesorgt, dass Tracking (und dessen Analyse) zu Containern obendrauf kommen wird. Zumindest langfristig. Dafür braucht es ein offenes, multi-stakeholder-fähiges System, egal wie es am Ende technisch umgesetzt wird.
Weiterführende Links:
- How Chinese Drones Could Defeat America
- An astonishing raid deep inside Russia rewrites the rules of war (The Economist)
- NYT: Ukraine’s attack exposed America’s Achilles’ heel
- Bloomberg: Ukraine’s Drones Explainer
🤖 KI
Informelle Prozesse in Organisationen vs. KI-Verbreitung
Ein Thema, mit dem wir uns hier regelmäßig beschäftigen, sind die Fallstricke, die Hürden und Hemmnisse, welche die Verbreitung von KI verlangsamen.
In diesem Post auf X werden wichtige organisatorische Hürden angesprochen:
- Viele wichtige Prozesse sind nicht präzise dokumentiert. Diese Prozesse sind entscheidend, und "es gibt große Risiken, wenn die Prozesse nicht eingehalten werden."
- KI hat Schwierigkeiten, implizites Wissen zu erlernen. "AI agents can't learn it by trial and error because the costs... rarely materialize."
In most organizations, there exist important processes with these 4 properties:
1. They aren't written down, or at least not precisely enough for AI agents to comply with.
2. They are essential for proper functioning — there are big risks if the processes aren't adhered to.
3. Those risks only surface once in a while.
4. The processes may have been performed for so long that they are "just the way things are done around here"; people may have forgotten the original reason why the process was deemed necessary, and may not be able to explain it.
Ein Beispiel dafür sind etwa informelle Vorbriefings von Aufsichtsräten vor den offiziellen Sitzungen:
pre-briefing board members to avoid surprises at board meetings. Here's my prediction. It will prove extremely challenging for AI agents to learn this kind of tacit knowledge. They can't learn it by trial and error because the costs, while high, rarely materialize, limiting opportunities for learning. Maybe human workers will train AI agents in the same way they train junior workers, but this is a very different kind of "learning" compared to machine learning and will require new technical paradigms.
Man sollte allerdings folgende Dinge im Hinterkopf behalten:
- Diese Hürden sind nicht für alle gleich. (Insert Gibson-Zitat hier.)
- Bedeutet z.B.: Je älter und größer eine Organisation, desto mehr implizite Regeln hat sie. Umso schwerer wird es ihr also fallen, die KI effektiv in der Organisation einzusetzen.
- Diese impliziten Hürden werden umso mehr ins Gewicht fallen, je besser KI wird, besonders mit Agenten, also autonom und semi-autonom handelnde KI. Dafür muss eine KI den Kontext verstehen, in dem sie liefern soll.
- Konkret bedeutet das: Die Ausschöpfung des Potenzials von KI wird sehr, sehr ungleich verteilt werden (Komm nochmal kurz her, William). Junge, neue Unternehmen, AI-First-Unternehmen, haben einen riesigen Vorteil. Regionen, welche die Gründung neuer Unternehmen erleichtern, haben einen enormen Vorteil.
Cursor und die Bedeutung eigener Modelle
Briefing 262: Tech- und KI-Trends, Spannendes aus der KI-Forschung 30 May 1:34 AM (4 months ago)
Hi,
aufgrund von Feiertag und langem Wochenende heute ein etwas anderes Briefing mit unter anderem Verweisen auf viele interessante KI-Papers. Und Zahlen und Grafiken.
Marcel
Zitat des Tages
People don't fully realize how mind-blowing cameras actually are. We took minerals from the Earth - glass, metal, silicon - and engineered a way to freeze moments in time. A literal snapshot of reality, built by creatures on a spinning rock, using dust from that very rock.
🤖 KI
Neben Robotern arbeiten
Zu viel Robotik rund um den eigenen Arbeitsplatz hat einen demotivierenden Effekt.
In meinen Augen noch offen: Liegt das an den starren Abläufen klassischer Robotik oder an Robotern allgemein?
Also, wird dieser Effekt mit den kommenden flexiblen, LLM-getriebenen Humanoiden verstärkt oder geschwächt?
Diffusionsmodelle für Text
Einmal im Monat fasse ich spannende Forschungen zu KI-Themen zusammen.
Dieses Mal nehme ich Bezug auf das letzte Woche von Google vorgestellte Diffusionsmodell für Text. Diffusion benutzen wir eigentlich für Bild- oder Videogenerierung. Bei Text hat Google damit eine erstaunliche Geschwindigkeit hinbekommen:
Gemini Diffusion kann bis zu 2.000 Token pro Sekunde erstellen. Das vergleichbare transformerbasierte LLM Gemini 2.0 Flash-Lite erzeugt 163 Token pro Sekunde.
In der Forschung wird schon längst mit Diffusionsmodellen für Text experimentiert. Neben drei aktuellen Papers zu diesem Thema geht es außerdem darum, dass Forschende festgestellt haben, dass das mittlerweile von besseren Modellen abgelöste o1-preview übermenschliche Diagnosefähigkeiten hat.
Und dazu passend: Eine offene LLM-Familie für den Medizinsektor aus Spanien.
Die KI-Papers in F.A.Z. PRO Digitalwirtschaft.
Trends in KI und Tech allgemein
Briefing 261: Die neue Tech-Ära 25 May 6:23 AM (4 months ago)

Hi,
alles neu macht der Mai.
Marcel
Im Fokus dieser Ausgabe:
- Eine neue Tech-Ära: Apple und Google verändern sich, neue globale Player kommen nicht aus den USA, und KI wirbelt alles durcheinander.
- OpenAI baut KI-First-Geräte: Ein Blick auf den Unterschied zwischen mobilen OS und Desktopsystemen gibt uns einen Hinweis darauf, worum es bei KI-First-Geräten gehen wird.
- Chips: Die EU hat ein Problem.
- und mehr
Zitat des Tages
Agents are models using tools in a loop.
Hannah Moran von Anthropic (via)
Eine neue Tech-Ära
Als ich am Anfang der neuen Exchanges-Folge 375 darüber sprach, dass es sich gerade anfühlt, als würde eine neue Ära in Tech im weitesten Sinne beginnen, war die Übernahme von Jony Ives io durch OpenAI noch nicht verkündet. Das passt aber natürlich hinein.
Hier ein paar Punkte, warum längst eine neue Ära begonnen hat:
- Die Grundpfeiler des westlichen Internets waren lange amerikanisch: Google, Microsoft, Apple, Meta, Airbnb, Uber, etc. Sogar Wikipedia war eine Idee aus den USA. Seit einigen Jahren sieht das anders aus: Globale Player aus Asien übernehmen immer mehr Teile des Internets. TikTok ist neben YouTube zum wichtigsten Ground Zero der heutigen Kultur geworden. Tein, Shein und Co. rollen den (Online-)Handel auf. Es ist auch nicht auf China beschränkt: Shopee kommt aus Singapur, Coupang aus Südkorea, und alle drängen mit vollen Kriegskassen auf neue Märkte wie Europa. Das kommt zur Dominanz der industriellen Massenfertigung in China noch obendrauf. Es wird meiner Ansicht nach noch viel zu wenig über die Implikationen gesprochen. (Spätestens seit Deepseek sollte außerdem allen klar sein, dass auch KI kein reines US-Thema mehr ist. Chinas Modelle, das wissen Briefing-Lesende, sind längst an der Weltspitze dabei.
- Google muss seine Suche wegen KI umbauen. Und das tun sie nun. Erste Schritte wurden auf der I/O vorgestellt. Roland Eisenbrand von OMR: “Zunächst einmal ganz nüchtern mit Blick aufs Marketing: “Wenn künftig jede*r Nutzer*in zunehmend unterschiedliche Suchergebnisse ausgespielt werden, teilweise auf Basis von Inhalten und des Verhaltens außerhalb der Google-Suche (etwa in Gmail und Maps) – worauf sollen Suchmaschinenoptimierer*innen künftig noch optimieren?“
Künftig ist eine Basis der Internet-Discovery: LLMs statt statischere Machine-Learning-Rankings (vulgo “Google-Suche”) (Briefing 260) It’s going to be a different beast. - Apple war die 2010er und Anfang der 2020er unangreifbar. Ein Unternehmen auf Erfolgskurs, bei dem es kaum ein Argument gab, warum diese gut geölte Maschine ins Stocken geraten sollte. No more: Apple ist hilflos zurück beim Thema KI und, schlimmer noch, scheint sich auf Richtungen festzulegen, die sie nicht voranbringen werden. Hinzu kommt, was in den Apple-nahen Medien aktuell diskutiert wird: Die Entwicklercommunity wird von Apple so schlecht behandelt, dass Unbehagen offenem Hass gewichen ist, also semi-offen: Weil nur die wenigsten öffentlich Apple zu kritisieren wagen. Wenn Apple-Fan Nr.1 John Gruber “Something Is Rotten in the State of Cupertino" schreibt, dann ist es ernst. Hinzu kommen Zölle und Ex-Apple-Star Jony Ives neues Projekt (siehe unten). Allein die Zusammenfassung der letzten Woche für Apple ist brutal.
- KI: Vibe Coding, Buy for me, KI-Browser, Agents, do I need to go on. KI ist für das Internet, was die Industrialisierung für die prä-industrielle Gesellschaft war.
- Die turbulenter werdenden geopolitischen Entwicklungen machen die bereits volatilen Tech-Themen noch volatiler.
Der Medienexperte Brian Morrissey über “Henry Blodget's New New Thing", der jetzt einen Substack-Newsletter mit Abo-Funktion gestartet hat, also das genaue Gegenteil zu Blodgets vorheriger Publikation, Business Insider:
Now publishers need to prepare for Google Zero, as AI roils search distribution and the inevitable takes hold: Search traffic is in secular decline. This is a structural, not cyclical, change that will make formerly successful models obsolete.
Die gesamte Internetökonomie, wie wir sie die letzten 20 Jahre im Westen kannten, verschiebt sich. Für Expert:innen besteht darin kein Zweifel.
🤖 KI
Ive + Altman: OpenAI-Gadgets, aber wie? - Allgemeine Gedanken dazu (Potenziale, Richtungen)