Serializing an enum with System.Text.Json 3 Jan 4:41 PM (9 months ago)
Turns out that json serialized enums with System.Text.Json is pretty annoying. I just wanted the enum serialization/deserialization to work, but they don’t. Here is how I expected them to work.
- Serialize to string.
Not Met: They serialize to a number by default. - Deserialize from string.
Not Met: They deserialize only from numbers by default and throw an exception if a string is passed in. - Deserialize from case-insensitive string.
Not Met: They deserialize only from numbers by default and throw an exception if a string is passed in. - Deserialize from a number.
Met: This worked.
So, I wrote (with the help of AI) a Json enum converter that does this. It took a few classes
using System.Text.Json.Serialization;
namespace Rhyous.Serialization;
/// <summary>A JsonConverter factory.</summary>
public static class EnumJsonConverterFactory
{
/// <summary>Creates a JsonConverter.</summary>
/// <typeparam name="T">The type of JsonConverter to create.</typeparam>
/// <param name="useCamelCase">Whether to use camel case or not.</param>
/// <returns>The JsonConverter.</returns>
public static JsonConverter CreateConverter<T>(bool useCamelCase) where T : struct, Enum
{
return new JsonStringOrNumberEnumConverter<T>(useCamelCase);
}
}
using Session.Extensions;
using System.Collections.Concurrent;
using System.Reflection;
using System.Runtime.Serialization;
using System.Text.Json;
using System.Text.Json.Serialization;
namespace Rhyous.Serialization;
/// <summary>Custom JsonConverter for enums to handle both string and numeric representations, including support for EnumMemberAttribute.</summary>
/// <typeparam name="T">The enum type to be converted.</typeparam>
public class JsonStringOrNumberEnumConverter<T> : JsonConverter<T> where T : struct, Enum
{
private static readonly ConcurrentDictionary<Type, ConcurrentDictionary<string, T>> _enumMemberCache = new();
private readonly bool _camelCase;
/// <summary>The constuctor.</summary>
/// <param name="camelCase"></param>
public JsonStringOrNumberEnumConverter(bool camelCase = false)
{
_camelCase = camelCase;
}
/// <summary>Reads and converts the JSON to the enum value.</summary>
/// <param name="reader">The Utf8JsonReader.</param>
/// <param name="typeToConvert">The type to convert.</param>
/// <param name="options">The JsonSerializerOptions.</param>
/// <returns>The enum value.</returns>
public override T Read(ref Utf8JsonReader reader, Type typeToConvert, JsonSerializerOptions options)
{
if (reader.TokenType == JsonTokenType.String)
{
var enumText = reader.GetString();
if (TryGetEnumValue(enumText, out T value))
{
return value;
}
}
else if (reader.TokenType == JsonTokenType.Number)
{
if (reader.TryGetInt32(out int intValue))
{
if (Enum.IsDefined(typeof(T), intValue))
{
return (T)(object)intValue;
}
}
}
throw new JsonException($"Unable to convert json value to enum {typeToConvert}.");
}
/// <summary>Writes the enum value as a string.</summary>
/// <param name="writer">The Utf8JsonWriter.</param>
/// <param name="value">The value to write.</param>
/// <param name="options">The JsonSerializerOptions.</param>
public override void Write(Utf8JsonWriter writer, T value, JsonSerializerOptions options)
{
var enumMemberValue = GetEnumMemberValue(value);
writer.WriteStringValue(enumMemberValue);
}
private static bool TryGetEnumValue(string? value, out T enumValue)
{
if (value == null)
{
enumValue = default;
return false;
}
var enumType = typeof(T);
var enumMembers = _enumMemberCache.GetOrAdd(enumType, type =>
{
var members = new ConcurrentDictionary<string, T>(StringComparer.OrdinalIgnoreCase);
foreach (var field in type.GetFields(BindingFlags.Public | BindingFlags.Static))
{
var enumMemberAttr = field.GetCustomAttribute<EnumMemberAttribute>();
var enumValue = (T)field.GetValue(null)!; // An enum can't be null
if (enumMemberAttr != null && enumMemberAttr.Value != null)
{
members.TryAdd(enumMemberAttr.Value, enumValue);
}
else
{
members.TryAdd(field.Name, enumValue!);
}
// Add the numeric value as a string
var enumNumericValue = Convert.ToInt32(enumValue).ToString();
members.TryAdd(enumNumericValue, enumValue);
}
return members;
});
return enumMembers.TryGetValue(value, out enumValue);
}
private string GetEnumMemberValue(T value)
{
var enumType = typeof(T);
var field = enumType.GetField(value.ToString());
if (field == null)
{
throw new InvalidOperationException($"Enum value {value} not found in {enumType}.");
}
var enumMemberAttr = field.GetCustomAttribute<EnumMemberAttribute>();
if (enumMemberAttr != null && enumMemberAttr.Value != null)
{
return enumMemberAttr.Value;
}
return _camelCase ? ToCameCase(value.ToString()) : value.ToString();
}
private string ToCameCase(string value)
{
return char.ToLowerInvariant(value[0]) + value.Substring(1);
}
}
using System.Runtime.Serialization;
using System.Text.Json.Serialization;
namespace Rhyous.Serialization;
/// <summary>Custom JsonConverter Attribute for enums to handle both string and numeric representations, including support for <see cref="EnumMemberAttribute"/>,
/// and for writing enum values in camel case.</summary>
/// <remarks>If <see cref="EnumMemberAttribute"/> is used, it is output as is and the camel case setting is ignored.</remarks>
[AttributeUsage(AttributeTargets.Enum)]
public class JsonStringOrNumberEnumConverterAttribute : JsonConverterAttribute
{
private readonly bool _camelCase;
/// <summary>The constructor.</summary>
/// <param name="camelCase">Whether to use camel case or not.</param>
public JsonStringOrNumberEnumConverterAttribute(bool camelCase = false)
{
_camelCase = camelCase;
}
/// <summary>Creates the converter.</summary>
/// <param name="typeToConvert">The type fo convert.</param>
/// <returns></returns>
/// <exception cref="InvalidOperationException"></exception>
public override JsonConverter CreateConverter(Type typeToConvert)
{
var enumType = Nullable.GetUnderlyingType(typeToConvert) ?? typeToConvert;
var isNullable = Nullable.GetUnderlyingType(typeToConvert) != null;
if (!enumType.IsEnum)
{
throw new InvalidOperationException("JsonStringOrNumberEnumConverter can only be used with enum types.");
}
var createMethod = typeof(EnumJsonConverterFactory)
.GetMethod(nameof(EnumJsonConverterFactory.CreateConverter))!
.MakeGenericMethod(enumType);
return (JsonConverter)createMethod!.Invoke(null, new object[] { _camelCase })!;
}
}









A GitHub Action Template for a dotnet NuGet package 5 Mar 2024 5:00 AM (last year)
I’ve recently been using GitHub Actions a lot more heavily and as you know, I have a lot of GitHub repositories that become NuGet packages. I have been using AppVeyor and have had no issues with it. The only reasons I’m switching to GitHub actions is 1) to learn new things and 2) to be able to have the pipeline and source all in one site.
This GitHub action template will generate a NuGet package for any repository that is setup as a Microlibrary (See We are already in the age of Microlibraries).
Requirements to use the DotNet Nuget Package Workflow
This template is easy to use.
Requirements
- It is for a microlibrary.
A microlibrary is basically a repository with only one dll project. In C#, that means a repo is setup with only one Visual Studio solution that usually has two projects:- The DLL project
- The unit test project (The template will fail without a unit test project.)
- The template assumes you have everything in a directory called src.
- The solution is in the src directory.
- There is a nuget.config in the src directory
- The DLL project is configured to build a NuGet package on Release builds.
Note: Add this to your csproj file:<GeneratePackageOnBuild Condition="'$(Configuration)'=='Release'">True</GeneratePackageOnBuild>
- The GitHub actions template is not in the src directory, but in this directory
.github\workflows - This template publishes to NuGet.org and you must create a key in NuGet.org, then in GitHub repo settings, make that key a secret called:
NUGET_API_KEY
Options
Not everything is required.
- Versioning is created using the Build and typed in versions.
- Changing the version is easy. Just update the yml file.
- Want a new version to start at 0? (For example, you are at 1.1.25 and you want to go to 1.2.0)
- Simply set the base offset found below in the ‘# Get build number’ section of the template to subtract the build count.
For example, if you are on build 121 and your next build will be 122, set the value to -122.
- Simply set the base offset found below in the ‘# Get build number’ section of the template to subtract the build count.
- Code Coverage
- You can enforce code coverage and get a nice report in pull requests for the provided coverage.
- Chaning the code coverage percentage requirement is easy.
- Disabling code coverage is an option.
- The code coverage tool used doesn’t work with windows-latest. Notice the yml file says:
runs-on: ubuntu-latest
However, you can run on windows-latest, and this template will simply skip those lines.
- You can enforce code coverage and get a nice report in pull requests for the provided coverage.
- There is an option for you to have a vNext branch that will build prerelease versions.
If you want your vNext branch to be named something else such as future or current then you can just find and replace vNext with the desired branch name. - You can change the version of dotnet:
dotnet-version: [ ‘8.0.x’ ]
# Created by Jared Barneck (Rhyous).
# Used to build dotnet microlibraries and publish them to NuGet
name: CI - Main
# Controls when the workflow will run
on:
# Triggers the workflow on push events to the "master" or "vNext" branches
push:
branches: [ "master", "vNext" ]
paths-ignore:
- '**.md'
- '**.yml'
- '**/*.Tests/**'
- '**/.editorconfig'
- '**/.editorconfig'
- '**/.gitignore'
- '**/docs/**'
- '**/NuGet.Config'
- '.gitignore'
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
defaults:
run:
# There should only be one solution file (.sln) and it should be in the src dir.
working-directory: src
strategy:
matrix:
dotnet-version: [ '8.0.x' ]
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- uses: actions/checkout@v3
# Get dotnet setup and ready to work
- name: Setup .NET Core SDK ${{ matrix.dotnet-version }}
uses: actions/setup-dotnet@v4
with:
dotnet-version: ${{ matrix.dotnet-version }}
# Restore nuget packages
- name: Restoring NuGet packages
run: dotnet restore
# Get build number
- name: Get Build Number with base offset
uses: mlilback/build-number@v1
with:
base: -8
run-id: ${{github.run_number}}
# Build - Main
- name: Build source
if: github.ref == 'refs/heads/master'
run: dotnet build --configuration Release --no-restore -p:AssemblyVersion=1.3.0 -p:FileVersion=1.3.${{env.BUILD_NUMBER}} -p:Version=1.3.${{env.BUILD_NUMBER}}
# Build - vNext
- name: Build source
if: github.ref == 'refs/heads/vNext'
run: dotnet build --configuration Release --no-restore -p:AssemblyVersion=2.0.0 -p:FileVersion=2.0.${{env.BUILD_NUMBER}} -p:Version=2.0.${{env.BUILD_NUMBER}} --version-suffix alpha
# Run Unit Tests
# Add coverlet.collector nuget package to test project - 'dotnet add <TestProject.cspoj> package coverlet'
- name: Run Tests
run: dotnet test --no-build --configuration Release --verbosity normal --collect:"XPlat Code Coverage" --logger trx --results-directory coverage --filter TestCategory!=SkipCI
# Install ReportGenerator
- name: Install ReportGenerator
run: dotnet tool install -g dotnet-reportgenerator-globaltool
# Run ReportGenerator
- name: Run ReportGenerator
run: reportgenerator -reports:./coverage/*/coverage.cobertura.xml -targetdir:coveragereport -reportType:Cobertura
# Code Coverage
- name: Code Coverage Report
if: runner.os == 'Linux'
uses: irongut/CodeCoverageSummary@v1.3.0
with:
filename: '**/Cobertura.xml'
badge: true
fail_below_min: true
format: markdown
hide_branch_rate: false
hide_complexity: true
indicators: true
output: both
thresholds: '60 80'
- name: Add Coverage PR Comment
uses: marocchino/sticky-pull-request-comment@v2
if: runner.os == 'Linux'&& github.event_name == 'pull_request'
with:
recreate: true
path: code-coverage-results.md
# Publish NuGet
- name: Publish the NuGet package
if: ${{ (github.event_name == 'push' || github.event_name == 'workflow_dispatch') && github.ref == 'refs/heads/master' }}
run: dotnet nuget push "**/*.nupkg" --source "https://api.nuget.org/v3/index.json" --api-key ${{ secrets.NUGET_API_KEY }} --skip-duplicate
Where Y.A.G.N.I. falls short 7 Sep 2023 5:00 AM (2 years ago)
I am a big believer in the YAGNI (You aren’t gonna need it) principle. But it applies to features, not coding practices. It is more of a way to say: Code the MVP (minimal viable product) first. However, when applied outside of that realm, it can be harmful. For example, when talking about ‘how’ to write code, it often doesn’t apply because there are so many instances where you are gonna need it.
YAGNI is for what you code, now how you code.
With how you code, you are gonna need it:
- Quality – You are gonna need quality.
- Maintainability – You are gonna maintain it.
- Replaceability – You are gonna replace it.
- Testability – You are gonna test it
- Security – You are gonna need security.
Quality – You are gonna need quality
Code should always be written with quality. There are a lot of principles that are guidelines for quality, starting with SOLID. If you struggle to understand the SOLID principles or think they are too general, then I would suggest you follow my SOLID Training Wheels until you understand them better.
You may have heard of the Quality-Speed-Cost Triangle. The triangle is used in manufacturing with the following rule: You can only choose two of the three. Because code is like manufacturing, some believe this triangle applies to code. It doesn’t. Software is not physical, it is virtual. Once you create a piece of code, you can run that code a million times in what a human would consider almost instant.
You can use the Quality-Speed-Cost Triangle with code, but with code, the triangle does not have the same rules. For example, the rule that you only get two doesn’t apply. Why? Because Quality is the only way to get speed and low cost.
In code, the rule is: Quality gives you the other two.
Unlike manufacturing physical products, software actually gets faster and cheaper when you increase the quality. You can’t have code speed without code quality. You can’t have low cost with code quality.
So focus on SOLID. The S (Single Responsibility Principle) and I (Interface Segregation Principle) both actually mean smaller objects (mostly classes and methods) in code. Smaller building blocks lead to faster code. When you write with smaller building blocks, there is less duplication. Every line of code has a cost to both create and maintain. Duplicate code destroys speed and raises costs. So smaller or ‘single’ will always be cheaper and faster.
Maintainability – You are gonna maintain it
If your company goes out of business (or your open source project dies), maybe your code isn’t maintained. But is going out of business your goal? If not, then your code is going to last. Every line of code has a maintenance cost.
The smaller or more ‘single (S in SOLID)’ the code is, the easier it is to unit tests, the less likely it is to have bugs, the less likely it is to change (part of O in SOLID), and the more like it is to be finished and never touched again. If most of your code is SOLID, small, unit-tested, replaceable building blocks, your maintenance costs will stay extremely low. Finished code leads to low maintenance costs.
Replaceability – You are gonna replace it
Systems die and get old. Code that uses systems will die with those systems. If the code is like the arteries in a human, entwined in everything everywhere, there is no replacing it. If the code is more like car parts, you can replace it with some work. If the code is more like computer peripherals, where you can add them, remove them, disable them in place, and replace them, then you are going to be faster. Quality is going to be easier because replacing pieces is going to be cheaper.
In SOLID, the S and I make things smaller, and usually (though not always) smaller is easier to replace. The O hints that you should replace code instead of changing code. The L and D are all about replaceability. Replaceability directly affects quality and future cost. If you are using MS SQL or Oracle and suddenly need to scale to hundreds of database servers on the cloud, you want your repository to be replaceable so you can migrate easily to a cloud database by replacing your repository.
Many companies who wrote monoliths without replaceable parts are now suffering this reality, as they either fail to replace their code with modern cloud architecture or spend exorbitant amounts to rewrite.
Every letter of SOLID in some way hints at replaceability. S – single, and it is easier to replace a single thing. O means the code is closed for changes, and so any new functionality goes in new code that likely replaces or extends the old code, the L is about replacing parent classes with child classes, and the I is about having small interfaces that are easily replaced with other implementations, and the D is literally about being able to inject any implementation from one to many interchangeable (or replaceable) implementations by inverting the dependency (The D is dependency inversion not depending injection, but a lot of people are now saying it is the latter).
Testability – You are gonna test it
This is almost the same as Maintainability, but while similar, it is different. Unit Tests help finish and close code without bugs. The more tests you have, the less likely you are to break anything as you add features to your code base.
SOLID doesn’t cover testing. But other principles, such as TDD, and industry standards, such as having greater than 70% code coverage (I say you should have 100% and close your code), all indicate that testability is key to speed and keeping costs down.
If everytime a dev makes a change, they introduce a bug due to lack of unit tests or automated tests, the costs will grow and the speed will slow as work stops to fix bugs.
However, if the tests warn you of the bugs as your are coding, the cost will stay low and there won’t be bumps (aka bugs) in the road slowing you down.
Security – You are gonna replace it
SOLID also doesn’t discuss security, but you are gonna need it.
So many people said they were never replace their database and yet are trying now to replace their database with cloud options.
Law suites from breached data are not cheap. Trying to bolt on security is not cheap. Unless you made everything easily replaceable, then it can be a low-cost task to replace implementations with secure implementations later in the process. If code is replaceable, adding security becomes much easier.
Conclusion
YAGNI is a good rule of thumb to live by for what you code, i.e. features and the MVP. However, YAGNI, will ruin your code base if you apply it to how you code.
Scenario Weaving – a Software Development Antipattern 15 Jun 2023 12:11 PM (2 years ago)
In Software Engineering, there is a term called Cyclomatic Complexity. It is a measurement of the number of branches in a method. There is a huge correlation between high Cyclomatic Complexity and bugs.
Today, I want to discuss an antipattern that leads to high Cyclomatic Complexity: Scenario weaving.
What is Scenario Weaving?
Scenario weaving is when a method handles multiple scenarios. Yes, this clearly breaks the Single Responsibility Principle.
Any time you see multiple “if” conditions in a method, you can be sure that the code is likely doing scenario weaving.
If you see a switch/case statement, you can be 100 sure that the code is doing scenario weaving as each case is a scenario. By the way, you should almost never be using the switch/case statement anymore. See What to do instead of using switch/case.
Scenario Weaving Example
This is a bad, antipattern example of scenario weaving.
This is simple example Cookie Monster code. For each cookie type, have the closest monster that likes that cookie type eat it.
public void EatCookie(Cookie cookie)
{
if (cookie.Type == "ChocolateChip")
{
if (chocolateMonster.IsCloser())
chocolateMonster.Eat(cookie);
else if (cookieMonster.IsCloser())
cookieMonster.Eat(cookie);
}
if (cookie.Type == "MacadamianNut")
{
if (nutMonster.IsCloser())
nutMonster.Eat(cookie);
else if (cookieMonster.IsCloser())
cookieMonster.Eat(cookie);
}
// ...
}
What type of cookie and which monster is closer can create multiple scenarios. As you can see, this method is trying to handle all the scenarios. Multiple scenarios have been weaved together in this method. To add more scenarios, our code just gets more and more complex. It breaks every letter of SOLID, forces us to repeat code a lot breaking DRY and really becomes a beast to unit test. The more cookies, flavors, etc., the more complex this method gets.
Scenario Weaving Refactored Example
This is a good, best-practice pattern example of code that doesn’t use scenario weaving and has low cyclomatic complexity.
This is simple example Cookie Monster code. For each cookie type, have the closest monster that likes that cookie type eat it.
public class MonsterSelector : IMonsterSelector // Interface omitted for brevity.
{
// Maps each cookie type to the monsters that like that cookie type. Inject this in the constructor.
Dictionary<string, List<Monster>> _monstersByCookieType;
// Constructor - omitted for bevity
public IMonster SelectBy(ICookie cookieT)
{
var monsterList = _monstersByCookieType[cookie.Type];
return monsterList.SelectClosestMonster();
}
}
public void EatCookie(Cookie cookie)
{
var monster = monsterSelector.SelectBy(cookie);
monster.Eat(cookie);
}
What type of cookie and which monster is closer still creates the same multiple scenarios. However, the above code handles and infinite number of scenarios without change and without increasing complexity. Also, this code is really easy to unit test.
Yes, more cookie types can exist. Yes, more monsters can exist. Yes, monsters can be at various distances from a cookie. Doesn’t matter. The code works in every scenario.
Now, in this above naive case, we solved all scenarios with one piece of SOLID code. However, sometimes you might have specific code per scenario. Imagine that you have some Monsters that eat in a special way and inherit from the IMonster interface . You would have to write there special Eat method separately for each special monster.
The important concepts here:
- Create a scenario selector.
- Have code that handles each scenario and make sure that code all implements the same scenario handling method signature (i.e. a scenario handling interface).
Conclusion
Scenario weaving is an antipattern that leads to complex buggy code, where the bugs can affect multiple scenarios. Such code leads to low quality code that breaks SOLID and DRY principles and is difficult to unit test.
Scenario selecting and having separate code to handle each scenario leads to bug free code, or at least a bug only affects one scenario. Such code leads to high quality code that follows SOLID and DRY principles and is easy to unit test.
What is a Lazy Injectable Property in C#? 28 Apr 2023 10:08 AM (2 years ago)
The following is an example of a lazy injectable. If you are not working on legacy code without Dependency Injection (DI) and Inversion of Control (IoC) with constructor injection, then this article is likely not relevant to you.
/// <summary>This is an example of a Lazy Injectable that will eventually be replaced with constructor injection in the future.</summary>
internal IMyNewClass MyNewClass
{
get { return _MyNewClass ?? (_MyNewClass = new MyNewClass()); }
set { _MyNewClass = value; }
} private IMyNewClass _MyNewClass;
Another example is very similar but used IoC.
/// <summary>This is an example of a Lazy Injectable that will eventually be replaced with constructor injection in the future.</summary>
internal IMyNewClass MyNewClass
{
get { return _MyNewClass ?? (_MyNewClass = IoCContainer.Resolves<IMyNewClass>()); }
set { _MyNewClass = value; }
} private IMyNewClass _MyNewClass;
Why use a Lazy Injectable?
Normally, you wouldn’t. Both examples above are antipatterns. In the first example, while it does use the interface, it also couples the code to an implementation. In the second example, it couples the code to an IoC container. This is essentially the well-known ServiceLocator antipattern.
However, it is very handy to use temporarily when working with legacy code to either write new code or refactor legacy code into with modern, quality coding practices. Even the top book on DI/IoC for CSharp mentions that less effective antipatterns can be usefully temporarily when refactoring legacy code.
Example Of When to Use
We all know that Dependency Injection (DI) and Inversion of Control (IoC) with constructor injection of interfaces, not concretes, is the preferred method of writing code. With DI/IoC and constructor injection, it is straight-forward to do object composition in the composition root. However, when working in legacy code without DI/IoC, that isn’t always possible to. Let’s say there is a class that is has over 100 references in code you can’t touch to the constructor. Changing the constructor is not an option. You need to change code to this legacy class. Remember, it doesn’t support DI/IoC with constructor injection and there is not composition root.
Let’s call this legacy class, MyLegacyClass.
However, you want to write you new code with DI/IoC with constructor injection.
public interface IMyNewClass
{
void SomeMethod();
}
public class MyNewClass
{
private readonly ISomeDependency _someDependency;
public MyNewClass(ISomeDependency someDependency)
{
_someDependency = someDependency;
}
public void SomeMethod()
{
// .. some implementation
}
}
So without a composition root, how would we implement this in MyLegacyClass? The Lazy Injectable Property.
public class MyLegacyClass
{
public MyLegacyClass ()
{
}
/// <summary>This is an example of a Lazy Injectable that will eventually be replaced with constructor injection in the future.</summary>
internal IMyNewClass MyNewClass
{
get { return _MyNewClass ?? (_MyNewClass = new MyNewClass()); }
set { _MyNewClass = value; }
} private IMyNewClass _MyNewClass;
public void SomeLegacyMethod()
{
// .. some implementation
MyNewClass.SomeMethod();
}
}
What are the benefits? Why would I do this?
You do this because your current code is worse and you need it to be better, but you can’t get from bad to best in one step. Code often has to refactor from Bad to less bad, then from less bad to good, and then from good to best.
New code using new best-practice patterns. New code can be easily unit-tested.
Old code isn’t made worse. Old code can more easily be unit tested. The Lazy part of the property is effective because the interface can be mocked without the constructor of the dependency ever called.
This Lazy Injectable Property basically creates a micro-composition root that you can use temporatily as you add code or refactor. Remember, the long-term goal is DI/IoC with constructor injection everywhere. The process has to start somewhere, so start with new code and then require it for changed code. Eventually, more and more code will support constructor injection, until after a time of practicing this, the effort to migrate fully to DI/IoC with constructor injection everywhere becomes a small project.
Is your code a bug factory? 16 Jan 2023 4:15 AM (2 years ago)
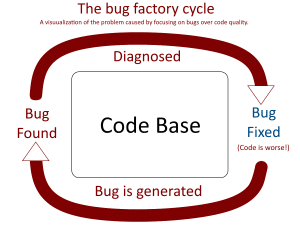
Many code bases are “working” but not quality. Often, there are so many bugs coming in, it is hard to work on new features. It can be hard to express to upper management why so many bugs exist. This is a quick estimate evaluation that easily give you a quantifiable number representing
whether you are bug factory or not.
You’ve heard the saying, “An ounce of prevention is worth a pound of cure.” Well, in code, you can say: And ounce of quality will prevent a pound of bugs.” But a saying is just that. How can we make that measurable? This questionnaire will do just that: make this saying measurable.
This is a golf-like score where the lower, the better. The highest score (bad) is 1000.
| YOUR SCORE % | QUESTION | DEFAULT VALUE | NOTE 1 | NOTE 2 |
|---|---|---|---|---|
| Is your code Tested? | Non-scoring header line. | |||
| What percent of your code is not covered by unit tests? | 200 | Enter the % of uncovered code, multiple by 2. | Use the default value of 200 if you don’t know the code coverage or don’t have unit tests. | |
| When you fix a bug, do you first create a unit test that exposes the = bug? |
50 | Enter the estimate % of times this is not practiced, divided by 2. | Use the default value if you don’t expose the bug with a Unit Test be= fore fixing it. |
|
| What percent of your customer use cases are not covered by automated tests? |
100 | Enter the % of customer use case that are not covered. | Use the default value of 100 if you don’t have this information. | |
| Does your code follow common Principles such as 10/100, S.O.L.I.D. or DRY |
Non-scoring header line. | |||
| What percent of the code breaks the 10/100 principle? |
125 | Enter the % of code that doesn’t follow the 10/100 principle, multiple by 1.25. | Use the default value of 125 if you have a lot of large files and methods or you don’t know the % of code that follows the 10/100 principle. |
|
| S – What percent of classes have more than 1 responsibility? | 100 | Enter the % of classes that break the S in SOLID? Hint: Estimate 1 responsibility for every 50 lines. | If you can’t get this information easily, use the default of 100. | |
| O – What percent of your code never changes because it is tested, stable, bug free, and open for extension? |
50 | Enter the % of classes that never change but can be extended? | Use the default of 50 if you have no idea. | |
| L – Do you have a best-practice for testing inheritance? | 25 | Enter the % of inherited classes that don’t have inheritance tests divided by 4. | If you don’t know what the L means and/or no inheritance tests exist, use the default of 25. |
|
| I – What percent of interfaces have more than 10 methods/propert ies? |
50 | Enter the % of interfaces that have more than 10 combined methods and properties, divided by 2. | Use the default value if you don’t know, or if the code has few interfaces. | |
| D – What percent of you code is using dependency injection? | 150 | Enter the % of classes that don’t use Constructor Injection, multiplied by 1.5. | Use the default value if you aren’t using DI. If you have DI but don’t use it properly do 75%. |
|
| DRY – Do you have standards and practices to prevent duplicate code? | 50 | Enter the % of code that could be considered duplicate code, divided by 2. | Use the default of 50 no standards to prevent duplicate code exist. If you have common libraries but they are a mess, use 25%. | |
| Do you do pair programming at least 1 hour a week? | 25 | Enter the % of developers that do not practice pair programming for 1 hour as week. | Use the default if pair programming is not a weekly practice. | |
| Do you require code reviews? | 25 | Enter the % of check-ins that do not have code reviews, divided by 4. | Use the defaul if you don’t require check-ins. If you require code reviews but have no standard code review check list, enter 13. | |
| Do you have a 1-step CI/CD process to 1) build, 2) run unit tests, 3) deploy, 4) run automated tests, 5) gating each check-in? | 50 | Enter 0 if you have it all. Enter 10 for each step you don’t have. | Use the default of 50 if you don’t have any of it, or if devs can build locally in 1 step after check-out. |
Now, add up the score in each column. Enter the score into this statement.
This code is ______ times more likely to create bugs than average.
Reacting to the Code Score
These are generalizations about what to do based on your score.
Warning! Neither me nor this blog are your company’s CTO or expert. Each project is different. These generalized suggestions should be analyzed by a company’s CTO and the expert team members the CTO trusts. It is solely their responsibility to make any decisions.
| 1000 | Max Worst Possible Score. |
| 700+ | Emergency: The code is in trouble and needs everything refactored, which will be very expensive. You need to heavily weigh the pros and cons of a rewrite. For both a rewrite or a refactor, much of the code and logic can remain in place. One option is to bring in an expert who can help you follow the strangler pattern to replace your code with new code a piece at a time. If the code is a coupled single piece, there may be prerequisite projects to decouple a piece. |
| 300-499 | There may be a few problem areas. Track bug areas and improve the code quality of those buggy areas. You may need to look at the code weaknesses and address them as projects, as incremental improvements may not be enough. |
| 100-299 | There may be a few problem areas. Do incremental improvements. |
| < 100 | Keep up the good work. |
So now you know whether your code is a bug factory or not. Congratulations on knowing the state of your code.
How to rate your code from 1 to 10? 9 Jan 2023 4:00 AM (2 years ago)
Rating code can be hard. Especially when reports to upper management are required. This can seem difficult and daunting. However, it doesn’t have to be. The following questions can be answered in 5 minutes by someone with as little as 90 days in a code base. Or it can take someone unfamiliar with the code base time to do some spot checks (at least 5).
I’m not saying this is the most accurate measure. Neither is T-Shirt sizing a story. This is a quick generalization that actually works for rating code quickly. I’m not saying a full tech audit should be replaced with this simple questionnaire, but you are less likely to be surprised by a tech audit’s results if this is done this first. Also, this will give plenty of ideas for what to work on.
10 out of 10 Code
This is a simple code quality questionnaire.
Note: If a lead dev can answer this off the top of their head, great, have them do so. Otherwise, this may take time. Each question has some hints underneath with questions that can be answered positive and negatively and how to check some objects. The scoring assumes 5 objects are checked. Spot checking 5 objects from various parts of the code should be enough.
Scoring:
- Yes = 1 (positive answers and 4 out 5 object checks is a yes, otherwise, it is a no.)
- No = 0
Questionnaire:
- The code has 70% code coverage.
Just trust your coverage tool. But you should know not all coverage tools are the same. For example, if testing a bool, if only one test exists passing only true or false but not both, one code coverage tool might call it 100% covered and one might consider it 50% covered. - S = Single Responsibility Principle
Does each object in your code have 1 responsibility? Don’t know off the top of your head? Check 5 classes from various parts of the code base. Think smaller. Broad responsiblities are not single. - O = Open/Closed Principle
Does your architecture lend to avoiding breaking changes. Look at a number of check-ins that touch existing code. Do they include breaking changes (i.e. a change to a public signature.) - L = Liskov Substitution principle
Find inherited classes. Should they be using inheritance or should they have been written with a “has a” over an “is a”. Do they have the ability to crash where a parent wouldn’t?
If you don’t use inheritance because you always use “has a” over “is a” or because you always use interfaces, then give yourself a yes here. - I = Interface segregation principle
Check your interfaces, are they very small? No more than 5 total properties/methods on the interface on average?
If most objects don’t have interfaces, this is a fail. - D = Dependency Injection (with most objects using constructor injection)
Does the code entry points have a composition root? Yes/no? Alos, check 5 classes from various parts of the code base. How many classes use constructor injection? 95%? Yes/no? - Dry = Don’t Repeat Yourself (the inverse of S, not only one responsibility, but no more than one class has that one responsibility).
Do you have duplicate code doing the same thing? Are there groups of lines copy and pasted in many places, etc. If you have almost no duplicate code, you get a point here, otherwise, if you have lots of duplicate code, you don’t get a point here. - Cyclomatic Complexity average under 3.
What are the average number of branches in a method? Don’t know. Spot check 5 methods from different parts of your code. Or just guess based on number of lines in a method. Not including the signature, are the guts of each method 10 lines or less with an average of 5 lines. - The code follows 90% the Joel Test and/or the 12 factor app?
Google “Joel Test” or “12 factor app” – If you follow 90% of the items on those lists, you get a point, otherwise you don’t - The code has a gated CI/CD end-to-end pipeline that goes all the way to production
- Applications’ CI/CD pipeline includes 2 code reviews, build, unit tests, deploy, automated tests only deployed environment, then only if all passes, a merge to master is allowed, and after check-in, the main build repeats much of the above and deploys all the way to production?
- Library’s CI/CD pipeline includes 2 code reviews, build, unit tests, runs any automated tests, then only if all passes, a merge to master is allowed, and then the library is published as package.
- Even if you are at 0, if your code is working and making your company money, and still selling new customers, give it a +1. Bad code that works is still a solution and is still better than nothing and deserves 1 point.
What is your code quality score out of 10?
Reacting to the Code Score
These are generalizations about what to do based on your score.
Warning! Neither me nor this blog are your company’s CTO or expert. Each project is different. These generalized suggestions should be analyzed by a company’s CTO and the expert team members the CTO trusts. It is solely their responsibility to make any decisions.
- If you are 10 out of 10, keep doing what you are doing.
- If you are 7-9 out of 10, keep doing incremental improvements.
- If you are 4 to 6 out of 10, you may need to look at your weaknesses and address them as projects, as incremental improvements may not be enough.
- If you are 2-3 out of 10, you need multiple major refactor projects. Likely you don’t have Dependency Injection. Start your big projects by adding it.
- If you are 1 out of 10, you need everything refactored, which will be very expensive, and you need to heavily weigh the pros and cons of a rewrite. For both a rewrite or a refactor, much of the code and logic can remain in place. One option is to bring in an expert who can help you follow the strangler pattern to replace your code with new code a piece at a time. If the code is a coupled single piece, there may be prerequisite projects to decouple a piece.
Congratulations on knowing the state of your code.
Mono Repo vs Micro Repo – Micro Repo wins in a landslide 25 Aug 2022 3:28 PM (3 years ago)
A while back, I had to make the decision between a MonoRepo or a Micro Repo for my Rhyous libraries.
I chose Micro Repos because it seemed to be “common sense” better. I’m so glad I did.
What is a Mono Repo?
1 Repo for all your projects and libraries
What is a Micro Repo? (i.e. Poly Repo or Multi Repo)
1 Repo for 1 library. Sometimes Micro Repos are called Poly Repos or Multi Repos, but those terms don’t really imply the the 1 to 1 ratio or the level of smallness that Micro Repo implies.
Why My Gut Chose Micro Repos
I do not have the amount of code a large company like Microsoft or Google has. However, for the average developer, I have way more open source projects on my GitHub account.
Despite choosing micro repos over a mono repo for my open source, I have more experience with mono repos because the companies I worked for have had mono repos. Also, I chose a mono repo for a couple of my open source projects. I have zero regrets for any of my poly repos, but I regret all of my mono repos.
My employers were mono repos because they grew that way. It wasn’t a conscious, well-informed decision. To the last of my knowledge, they continue to be mono repos only because they are stuck. It is too hard (they think) to break up their mono repo.
I do not enjoy working with my mono repos.
It might sound awesome to have everything in one place. It isn’t. We’ve already proven this time and again.
Stop and think about what it looks like when you put all your classes and methods in one file. Is it good?
Think about that for a minute. Smaller is almost always better.
If this article sounds bias toward micro reops, it probably is, because I have long ago seen micro repos as the clear winner to this argument and struggle to find reasons to support a mono repo.
The goal of this article, is to show that the move to microservices isn’t the only recent movement, as we are well into the age of Microlibraries, and the move to microservces and microlibraries also includes a move to micro repos.
GitHub won the source control world and dominates the market. They won for many reasons, but one of those reasons is how easy they made working with micro repos.
The Dev world is better with micro repos. Your source code will be better with micro Repos.
I am writing a book called “Think Smaller: A guide to writing your best code” and before I unequivocally declare micro libraries as the way to go, I need to do an analysis on it because gut feelings can be wrong. The goal of this analysis is to investigate if my gut was wrong. It pains me to say it, but my gut has been wrong before. This time it wasn’t. Now here is the analysis of why my gut was right.
Mono Repo
Mono Repo with:
- Direct project references (instead of use of package management)
- Automated CI/CD Pipelines
Pros of Mono Repos
If a pro that is shared with micro repos, it is not listed.
- Atomic Changes/Large-Scale Code Refactoring – For a given set of code openable by an IDE as one group of code (often called a solution) you can do large scale refactoring using the IDE. There is a lot of tooling in the IDE around this.
– However, when a mono repo has multiple solutions, you don’t get that for the other solutions. After that you have to write scripts, in which case, you get no benefit over micro repos.
Yes, it is true. I found only 1 pro. If you have a pro that is truly a pro of mono repo that can’t be replicated with micro repos, please comment.
Pros from other blog posts (Most didn’t stand up to scrutiny)
I did a survey of the first fie sites I found on a google search that list Mono Repo pros. Most of these turned out not to be pros:
- https://betterprogramming.pub/the-pros-and-cons-monorepos-explained-f86c998392e1
- https://fossa.com/blog/pros-cons-using-monorepos/
- https://kinsta.com/blog/monorepo-vs-multi-repo/
- *https://semaphoreci.com/blog/what-is-monorepo
- https://circleci.com/blog/monorepo-dev-practices/
* Only site that had real-world use cases.
Now, remember, just because someone writes in a blog (including this one that you are reading) that something is a pro or a con, you shouldn’t trust it without evidence and argument to back it up. A survey of such pros found most of the data is “made up” for click-bate. Most of the so-called pros and cons in these articles don’t hold up to scrutiny.
I will tag these blog-post-listed benefits after my analysis.
True = It is a benefit of only a mono repo
False = It is not a benefit of a mono repo at all. It is con listed as a pro.
Shared = You get this with both Mono Repos and Micro Repos
- One source of truth — Instead of having a lot of repositories with their own configs, we can have a single configuration to manage all the projects, making it easier to manage.
(False)
Why false? Micro libraries are actually more of a single source of truth for any given piece of code. With a mono repo, every branch has a copy of a library even if there are no plans to edit that library. Many teams end up using many branches. Teams end up with dozens of branches and no one ever knows which ones have changes or not. Devs often don’t know which branch has the latest changes. There is nothing further from one source of truth. - Code reuse/Simplified Dependency Management — If there is a common code or a dependency that has to be used in different projects, can it be shared easily?
(Shared or False)
Why Shared? Sharing code is just as easy with Micro Repos. Publish the code to a package management system and anybody can share your code.
Why False? There are huge burdens to sharing code as files as opposed to using a package managers such as npm, maven, nuget, etc. If 10 separate projects share code, and you need to update something simple such as folder layout of that code, you now can’t change a folder layout without breaking all 10. You have to find every piece of code in the entire repo that references the code and update all of them. You might not even have access to them all as they may be owned by other teams. This means it takes bureaucracy to make a a change to reused code. If a design (mono repo) leads to a state where doing something as simple as moving files and folders breaks the world, how can you call that design a pro and not a con? - Transparency — It gives us visibility of code used in every project. We will be able to check all the code in a single place.
(Shared)
Why Shared? Well, with Micro Libraries, just because they are separate repos doesn’t mean they aren’t in one place. Whether you are creating your repos in public GitHub, GitHub Enterprise, BitBucket, Amazon, Azure, or wherever, you still have your code in one place. - Atomic changes/Large-Scale Code Refactoring — We can make a single change and reflect the changes in all the packages, thus making development much quicker.
(True)
This is true. If you want to change something that affects an entire repo, or even a handful of projects in a repo, you can do it faster in mono repo.Careful, however. While this is true, this breaks the O in SOLID. If a library has to update all its consumers, it probably isn’t doing something right in the first place. This is an architectural warning sign that your architecture is bad. A second issue is that this ability also means you can make sweeping breaking changes. - Better Visibility and Collaboration Across Teams
(Shared)
Why Shared? Because with Micro Repos everyone can still have read-only access to all repos. They can still know what other teams are doing.Tooling is what matters here. With GitHub, I can search for code across multiple repos. A dev doesn’t have to be in a mono repo to see if code already exists. In fact, repo names give you one more item to search on that mono repos don’t have, which can help search results be better in micro repos than in mono repos. -
(False) Lowers Barriers of Entry/Onboarding — When new staff members start working for a company, they need to download the code and install the required tools to begin working on their tasks
Why False? A mono repo does not do a new developer any favors. This actually is more of a con than pro. There is no evidence that this a pro, while there are evidences that it is a con. A new dev has to check out often gigs of code. The statement “they need to download the code and install the required tools to begin working” implies they need to download all the code. If you have 100 GB, or even 10 GB, is checking all that out easier when onboarding someone? What about overwhelming a new dev? With a micro library, a new dev can download one micro repo, which is smaller, making it quicker to see, read, understand, run tests against, and code against. A new dev can be productive in an hour with a micro repo. With a mono repo, they might not even have the code downloaded in an hour, or even in the first week. I’ve seen mono repos that take three weeks to setup a running environment.
- Easy to run the project locally
(Shared)
This usually requires a script. In a mono repo, the script will be part of the mono repo. In a poly repo, you can have that script in a separate repo that a new dev can check out in minutes (not hours or days) and run quickly.
-This is about tooling, and isn’t a pro or con of either. - (False/Shared) Unified CI/CD – Shared pipelines for build, test, release, deploy, etc.Why false? Because sharing a pipeline isn’t a good thing. That is a con. That breaks DevOps best practices of developers managing their own builds. How can a dev have autonomy to change their pipeline if it affects every other pipeline?
Why Shared?
This is about tooling, and really is not a pro or con of either mono repos or micro repos. You can do this with either. However, it is far easier to get CI/CD working with micro repos.
Cons of Mono Repos
I was surprised by how the cons have piled up. However, it is not just important to list a con, but a potential solution to con. If there is an easy solution, you can overlook the con. If there is not an easily solution, the con should have more negative weight.
- Fails to prevent decoupling – Nothing in a mono repo prevents tight coupling by default.
Solution: There is no solution in mono repos to this except using conventions.Note: Requiring conventions is a problem. I call them uphill processes. Like water takes the easiest path, so do people. When you make a convention, you are making an uphill process, and like water, people are likely not to follow them. Downhill processes are easier to follow. So conventions require constant training and costly oversite.Because of coupling is only prevented by convention, it is easier to fall into the trap of these coupling issues.
There are many forms of coupling
- Solution coupling
- Project coupling
- File system coupling
- Folder coupling – Many projects can reference other files and folders. With mono repos you can’t even change file and folder organization without breaking the world.
- File coupling – Other projects can share not just your output, but your actual file, which means what you think is encapsulated in private or internal methods, might not be encapsulated.
- Build coupling – Break one tiny thing and the entire build system can be held up. Also, you can spend processor power building thousands of projects that never changed every build.
- Test coupling – Libraries can easily end up with crazy test dependencies.
- Release coupling – You can spend more money on storage because you have to store the build output of every library every time .
- Fails to Prevent Monoliths – By doing nothing to prevent coupling, it does nothing to prevent monolithic code
Solution: There is no solution in mono repos to this except using conventions.
Monoliths are not exactly a problem, they are a state of a base. However, Monolith has come to mean a giant piece of coupled software that has to built, released, and deployed together because it is to big to break up.Note: About doing nothing. Some will argue that it isn’t the repo’s job to do the above. I argue that doing nothing to help is a con. If someone is about to accidentally run over a child with their car, and you can stop it easily and safely, but you don’t, would you argue that doing nothing is fine because that kid isn’t your responsibility? Of course not. Doing nothing to help is a con. While a repository usually doesn’t have life and death consequences, the point is that failing to prevent issues is a con. - All Changes Are Major – A change can have major consequences. It can break the world. In a large mono repo, you could spend days trying to figure out what your change impacted and often end up having to revert code often.
Solution: None really. You can change the way you reference project, using package management, instead, which essential means you have micro repos in your mono repo. - Builds take a long time
Solution: None, really. If you change code, every other piece of code that depends on that code must build.
– Builds can take a long time because you have to build the world every time. - Mono repos cost more – Even a tiny change can cause the entire world to rebuild, which can cost a lot of money in processor power and cloud build agent time.
- Releases with no changes – Many of your released code will be versioned, new, yet has no change from the prior version.
- Not SOLID – Does NOT promote any SOLID programming, in fact, it makes it easier to break SOLID practices
Breaks the S in SOLID. MonoRepos are not single responsibility. You don’t think SOLID only applies to the actual code, right? It applies to everything around the code, too.- Because a repo has many responsibilities, it is constantly changing, breaking the O in solid.
- Increases Onboarding Complexity – It is just harder to work with mono repos as a new developer. One repo does nothing to easy a new developer’s burdens. In fact, it increases them.
Solution: Train on conventions. Train on how to do partial check-outs and often dependencies prevent this
– Developers have to download often gigs and gigs of data. With the world-wide work-anywhere workplace, this can take days for some offsite developers, and may never fully succeed.
– Overwhelming code base. - Security – Information disclosure
Solution: Some repo tools can solve this, but only if the code is not coupled.
– Easy to give a new user access to all the code. In fact, it is expected that new users have access to all the code.
– Often, you have to give access to the entire code base when only access to a small portion is needed. - Ownership confusion
Solution: None.
– Who owns what part of the mono repo? How do you know what part of a mono-repo belongs to your team?
– Does everyone own everything?
– Does each team own pieces?
– This becomes very difficult to manage in a mono repo. - Requires additional teams – Another team slows down build and deploy changes
Solution: None, really.
Team 1 – Build Team
Tends toward requiring a completely separate Build team or teams.
– A dev has to go through beuracracy to make changes, which . . .
– Prevents proper DevOps.Note: DevOps Reminder – Remember DevOps means that developers of the code (not some other team) do their own Ops. If you have a Build team, or a Deploy team, you are NOT practicing DevOps even if you call such a team a DevOps team. If I name my cat “Fish” the cat is still a cat, not a fish. A build team, a deploy team; even if they are called DevOps, they aren’t. In proper DevOps the only DevOps team is the DevOps enablement team. This team doesn’t do the DevOps for the developers, the team does work that enables coding developers to do their own DevOps more easily. If the same developers that write the code also write CI/CD pipelines (or use alrady written ones) for both Build and deploy autation, and the developers of the code don’t need to submit a ticket to the DevOps team to change it, then you are practicing DevOps.Team 2 – Repo Management Team
– No this is NOT the same as the build team.
– Many large companies are paying developers to fix issues with their repo software to deal with 100 GB sized repos.
– Companies who use mono repos ofte need a team to fix limitations with the software they use to manage their mono repo
Notice the list of cons piling up against mono repos. I’m just baffled that any one who creates a pro/con list wouldn’t see this.
Conclusion
The pros of mono repos are small. The cons of mono repos are huge. How anyone can talk them up with a straight face baffles me.
Warning signs that mono repos aren’t it isn’t all they are cracked up to be:
- The most touted examples of success are massive companies with massive budgets (Google, Microsoft, etc)
- Some of those examples show newer technology moving away from Monoreps
- Microsoft Windows is a Mono Repo
- dotnet core has 218 repositories and clearly shows that Microsoft’s new stuff is going to polyrepo
- Microsoft Windows is a Mono Repo
- Some of those examples show newer technology moving away from Monoreps
- A lot of the blogs for mono repos failed to back up their pros with facts and data
- Some of the sites are bias (sell mono repo management tools)
Micro Repo
Poly Repo With
– Microlibraries in a single git repo system with only one code project and it’s matching test project
– Each Releases to a Package Management Systems
– Automated CI/CD pipelines
– Shared Repo Container (i.e. all repos in the same place, such as GitHub)
===============================================================================================
Warning signs it isn’t all it’s cracked up to be:
– Big O(n) in regards to repos – you need n repos
Note: Yep, that is the only warning sign. So if you can script something.
Pros
Again, we will only list pros that aren’t shared with a mono repo
- Promotes Microservices and Microlibraries – Poly Repos promote microservices and microlibraries as a downhill process. Downhill means it is the natural easiest way to flow, and the natural direction leads to decoupling.
- A microservice builds a small process or web service that can be deployed as independently
- A microlibrary builds a small shareable library to a package management system for consumption.
- Easy to pass Joel Test #2 – Can you make a build in one step? Every microlibrary can make a build in one step. And if one of them stops doing it, it is often a 1 minute fix for that one microlibrary.
- Small repeatable CI/CD yaml pipelines as code
- Because the projects are micro, the CI/CD pipelines can be their smallest.
Note: This isn’t shared with a mono repo, as their CI/CD pipelines have to build everything. - They are also more likely to be reuseable.
- You can use the same CI/CD automation files on all microlibraries
- Almost every project can share the exact same yaml code, with a few variables
- Easy to find repeatable processes with tiny blocks
- Add a CI/CD pipeline to automatically update NuGet packages in your micro repos. This can also benefit your security, as your will always have the latest packages. When you use the correct solution, you start to see synergies like this.
- Because the projects are micro, the CI/CD pipelines can be their smallest.
- Prevents coupling (non-code)
- Prevents solution coupling
- Prevents project coupling
- Prevents file system coupling
- file coupling. You can’t easily reference a file in another repo. You can copy it and have duplicates.
- Prevents build coupling
- Prevents test coupling
- Prevents release coupling – New releases of libraries go out as a new package to your favorite package management system without breaking anyone. (see npm, maven, nuget, etc.)
- (Only doesn’t prevent code coupling)
- Builds are extremely tiny and fast – Building a microlibrary can take as little as a minute
- You can create a new build for a microlibary any time quickly
- Builds often you spend more time downloading package than building.
- Breaking a Microlibrary doesn’t break the world
- It creates a new version of a package, the rest of the world doesn’t rely on it
- With proper use of SemVer, you can notify your subscribers of breaking change for those who do need to update your package
- Completed microservices and microlibraries can stay completed
- A microservice or microlibrary that is working might never need to update to a new verison of a package
- Promotes SOLID coding practices for tooling around the code
– It follows the S in SOLID. Your repo has limited responsibilities and has only one reason to change.
– O in SOLID. Once a project is stable, it may never change, and may never need to be built/released again. - Simplifies Onboarding – A new dev can be product day 1 (and possible even the first hour)
– A new developer can check out a single repo, run it’s unit test, and get a debugger to hit a break point in about 5 minutes.
– Promotes staggered onboarding, where a developer can join, be productive on day one for any given repo, and then expand their knowledge to other repos.
– Any single micro repo will not overwhelm a new developer - Security – you can give a new developer access to only the repos they need access to.
- Single Source of Truth – A microlibrary is a single source of truth. The code exists nowhere else. Because it is a microlibrary (micro implying that it is very small), there will usually be no more than one or two feature branches at a time where code is quickly changed and merged.
- Promotes Proper DevOps – Devs can easily manage their own build, testing, and releasing to a package management system.
- Transitioning to Open Source is Easy – If one micro repo needs to go to open source, you just make it open source and nothing else is affected. (Be aware of open source licensing, that is a separate topic.)
- Ownership Clarity – Each repo has a few owners and it is easy to know who are the owners
- New Releases only when changed – The micro repo itself has to change, not new releases.
Pros that are shared
- Single Place for all your code – Storing all your repos in one repository system, such as GitHub can give you many of the benefits of a Mono repo without the cons.
- Code reuse/Simplified Dependency Management – Each micro repo hosts a microlibrary that publishes itself to a package management system for easy code sharing
- Better Visibility and Collaboration Across Teams – It is so easy to see when and by whom a change was made to a microlibrary.
- Easy to run a project locally
Cons
- Atomic Changes/Large-Scale Code Refactoring – Always hard to make sweeping changing anyway.
Solution: You can script these changes. You often still can do this, but not with IDE tools. This is- Inability to change your repos in bulk without scripting it. What if you need to change all your repos in bulk?
– 2 -things
1. This might not be a con. You will likely never have to do this. I almost put this in ‘Cons that aren’t actually cons’.
2. If you do need to do this, you can script this pretty easily. But you have to script it. So that is why I left it here in cons. - Doesn’t prevent code coupling – Just because you consume a dependency using package management, doesn’t automatically make your code decoupled.
Solution: None. Mono repo had no solution either, but at least all other coupling (folder, file, solution, project, etc. is prevented)
– You still need to practice SOLID coding practices.
– However, because the repo is separate, it becomes much more obvious when you introduce coupling. - Big O(n) Repos – You need a repo for every microlibrary.
– Can be overwhelming for a new developer to look at the number of repos.
Domain-based Repos
Domain-based Repos are another option. These are neither micro repos nor mono repos. If you have 100 libraries and 5 of them are extremely closely related and often, when coding, you edit those five together, you can put those in a single repo. For those 5 libraries, it behaves as a mono repo.
It is very easy to migrate from Micro Repos to Domain-based Repos. You will quickly learn which microlibraries change together. Over time, you may merge two or more microlibraries into a Domain-based Repo to get the benefits of atomic changes at a smaller level in a few domain-related micro libraries.
My recommendation is that you move to micro libraries and then over time, convert only the libraries most touched together into domain-based repos.
Example: My Rhyous.Odata libraries are a domain-based repo. However, I almost always only touch one library at a time now, so I’ve been considering breaking them up for two years now. It made sense during initial development for them to be a domain-based repo, but now that they are in maintenance mode, it no longer makes sense. Needs change over time and that is the norm.
Git SubModules
The only feature micro libraries doesn’t compete with Mono Repos on is atomic changes. With technology like git submodules, you may be able to have atomic changes, which is really only needed for a monolith. Everything is a microlibrary in a micro repo but then you could have a meta repo that takes a large group of micro libraries and bundles them together using git submodule technology. That repo can store a script that puts the compiled libraries together and creates an output of your monolith, read to run and test.
Conclusion
Micro Repo is the clear winner and it isn’t even close. Choose Micro Repos every time.
Once you move to micro libraries, allowing a small handful of Domain-based repos is totally acceptable.
Every Project is Different
There may be projects where a mono repo is a better solution, I just haven’t seen it yet. Analyze the needs of your project, as that is more important than this article or any other article out there.
Three divisions of code: Composition, Modeling, Logic 8 Aug 2022 4:50 AM (3 years ago)
Every developer wants to write good, clean code. But what does that mean? There are many principles and practices to software engineering that help lead to good code. Here is a quick list:
- 10/100 Principle
- S.O.L.I.D. Principles
- D.R.Y. Principle
- Principle of least surprise
- KISS – both Keep It Super Simple and Keep It Super Small
- YAGNI
- TDD
- Interface-based design or principle of abstraction
- Plan for obsolescence
- Principle of Generality
- Principle of Quality
- Data models have no methods
- Encapsulation similar to Law of Demeter
- Big Design Upfront or BDUF (which causes too many projects to fail and should be replaced with an MVP sketch up front)
- MVP – Minimal Viable Product
You can go look up any of those principles. However, it is hard to understand all of them while in college or even in the first five years of coding. Even developers who have coded for twenty years struggle to understand which principle to apply to which part of code and when.
What parts of your code do you apply these principles to? No, “Your entire code-base” is not actually the correct answer.
That leads to the three general divisions of code:
- Composition
- Modeling
- Logic
There are some other divisions that don’t exist everywhere, such as a user interface or UI. Many web services and APIs and libraries have no UI, so it isn’t a general division of all code. However, the UI that falls into all three of the above divisions. There are many other such examples of divisions of code that aren’t as general.
Composition
Composition is how your code is laid out. Composition involves,
- Files, folders, & Projects, and location of language objects in them
- Libraries, packages, and references
- How a project starts up
- How language objects (i.e. classes in OOO) interact
- Determining how your logic is called
- Determining how your models are created
- Layering your application and how interaction occurs between layers
Pieces of composition have models and logic related only to their pieces.
Common Principles used in Composition
Many of the principles and practices focus around this area. Are you using the D in SOLID, Dependency Inversion or DI for short? If so, you are working in the area of composition. In fact, a “composition root” is a common term when discussing DI. Are you using Interfaces-based design? Law of Demeter? Many of these are all in the area of composition.
- 10/100 Principle
- S. I. D. or SOLID (Especially Dependency Inversion)
- D.R.Y.
- KISS (both)
- TDD
- Interface-based design or principle of abstraction
- Principle of Quality
- Encapsulation similar to Law of Demeter
- Principle of Generality
- BDUF (or better, and MVP sketch)
Why are some left out? Well, YAGNI can be super destructive when it comes to composition. When you first start an app, it never needs a DI container, right? But you will regret following the YAGNI principle with that every time! When it comes to composition, you are going to need it.
What is the state or your composition?
Some basic questions to ask yourself to see if you have good composition?
- Do yo have a 1-step build?
- Do you have a single file for a single class or object?
- How does your program startup?
- How does it create new instances of classes and other objects? With a DI container?
- How does it configure settings? Is this clear, easy, and in one place? Can any class easily access those settings abstractly?
- Can you create integration tests that run any one unit or multiple units of your code with all external systems DBs, Web Services, File Systems, etc, faked or mocked?
- Do you find models and logic
When composition is done wrong or not understood, no amount of good modeling or good logic can save your code base. The composition has to be rewritten. Have you every heard these complaints?
- The code is hard to work with.
- The code is spaghetti code
- I have no idea how this code works
- Who wrote this code?
- It takes forever learn this code base
- It is a nightmare just to get this code to build
These are road-signs telling you that the composition has to be rewritten. Often, when someone has what would be called “bad” code, composition is what they are talking about. Vary rarely does a code-base need a complete rewrite. Often, it needs a composition rewrite. In fact, the entire movement to refactor to Microservices and Microlibraries is all about composition, or putting small bits of logic and modeling in one well-composed place because most monoliths did it wrong.
Modeling
This is the most obvious part of code. Creating models. Often they are simple data models, but modeling can get very complex (which you should avoid when possible because KISS, right?)
Almost anything can be modeled. A Person:
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
public int Age { get; set; }
}
Models can be small or big, though smaller is better.
Usually models are simple and easy to use. However, if you break some of the principles, models become difficult and cumbersome. For example, if you break the Data models don’t have methods principle, your models are now both modeling and providing logic, which could indicate the model now has two responsibilities, so the Single Responsibility Principle is broken.
Interfaces are automatically excluded from code coverage. Since data models shouldn’t have methods, they should not have tests. You can mark them as so, for example, in C# you can give a model class an attribute [ExcludeFromCodeCoverage], and there is likely an equivalent for whatever language or testing framework you are using.
Models are very common and there can be very many in a code base.
What do you model?
It is hard not to answer everything here, but really, you don’t model composition or logic. You model things. Nouns. Now, an action can be a noun, so while you don’t model logic, you might model a List<T> with an Add action, as it is common to add things to a list, however, the act of adding is not part.
Nouns represented in code are modeled. Data represented in code is modeled.
Behavior is modeled. Behavior is best described by an interface. All interfaces are models (not to be confused with data model classes, which is another type of modeling). Interfaces may be for composition or logic classes, and while the concrete composition or logic class itself isn’t a model, the creation of an interface is the act of modeling a single responsibility’s behavior.
Common Principles used in Modeling
- I in SOLID
- Principle of Quality
- Data models have no methods
- KISS (both)
- Principle of Generality (Think generics, such as modeling a list or collection with List<T>)
- Encapsulation similar to Law of Demeter (If your model is small enough and is shared between layers, it should be OK to be public right? Interfaces should be public, right?)
- TDD (except in data models, unless you break the Data models don’t have methods principle)
- YAGNI – helps keep models small
- Avoid model nesting hell (not a principle you hear much, but is very specific to models)
Notice this has way fewer principles than composition? That is because it is easier to do and more natural to get right.
What is the state or your modeling?
Some basic questions to ask yourself to see if you have good modeling?
- Are your models small and simple?
- Do you follow the Data models have no methods principle?
- Do you limit nesting of models? (Or do you have a nesting nightmare?)
- Does the code’s separate layers have their own models? Or do you practice model translation between layers?
- Does the average model have no more than 10 properties or fields?
Logic
When we talk about if conditions, looping, algorithms, data manipulation, hitting servers, reading or writing data, we are talking about the logic area. This is the meat of you code. This is where and how work gets done.
Logic classes are very common and there can be very many in a code base. When you are writing methods and doing things, you are writing logic.
What is the state or your logic?
Some basic questions to ask yourself to see if you have good modeling?
- Is all your logic decoupled into small 10/100 principle following single responsibility classes?
- If not, then, Oh, wait, that is composition and your composition is bad. Keep the logic, fix the composition.
- Is your logic code 100% unit tested?
- Does your logic code have parameter value coverage?
If you have bugs in logic, it is almost always due to lack of testing. 100% code coverage isn’t always enough if you don’t have parameter value coverage.
Common Principles used in logic
- 10/100 Principle
- S. and D. of SOLID – all dependencies should be injected and not part of a single responsibility
- D.R.Y. Principle – Don’t repeat your logic
- Encapsulation – Just make all your concretes private and their interfaces public and have a factory that returns concretes of interfaces
- KISS – both Keep It Super Simple and Keep It Super Small
- YAGNI – Don’t wrote logic you don’t need (unless you are writing an API for other consumers, then anticipated needs, prioritize them, get early customer feedback on them, and add them)
- TDD – Extremely important here as logic must be tested
- Interface-based design or principle of abstraction (almost a repeat of the D in SOLID)
- Principle of Generality – Sometimes, when the logic can be generic it should be
- Principle of Quality – Yes, this applies to all three
Developer Training Wheels for Writing S.O.L.I.D. Code 22 Jul 2022 8:29 AM (3 years ago)
When you first start riding a bike, most new bike riders (usually young kids) use training wheels. After a few months or years, those training wheels aren’t needed.
Similarly, when a developer writes code, he/she probably also needs training wheels. The difference is, that with code, you will almost always need these training wheels.
Note: After 20+ years of coding, despite a Master of Computer Science, despite being a Lead developer for over a decade, I still use these.
S.O.L.I.D. Training Wheels
S = Single Responsibility Principal
- Summary: 1 piece of code has 1 responsibility. The inverse: 1 responsibility of code has 1 piece of code
- Training Wheels:
- Follow the 10/100 Principle
- Do not write methods over 10 lines
- Do not write classes over 100 lines
- If you have to change a class that already breaks the 10/100 Principle:
- take your code out of that class and put it in a new class first so the original class is smaller
- Check-in this refactor without your new code
- make your changes in the new class
- Check-in your new code
- Think smaller.
- The smaller the responsibility, the better. Keep breaking down the responsibility until it so small you can’t split it
- The smaller the coding block, the more likely you will spot repetition
- Models already have a responsibility of being a model, and therefore should never have logic as that would be a second responsibility.
- Only one object per file (class, interface, struct, enum, delegate, etc.)
- Follow the 10/100 Principle
Note: The above are also the Don’t Repeat Yourself (D.I.Y.) training wheels
2. O = Open/Closed Principal
- Summary: If your code is marked as public, and you already have consumers the code (outside your solution), don’t break the code because it will break all the consumers code
- Training Wheels:
- Default to private or internal. Don’t make anything public unless you are sure it needs to be public.
- Give your unit test projects access to internals. For example, in C#, us [assembly: InternalsVisibleTo(“YourProject.Tests”)]
- For existing code, don’t change the code signatures (the way the class, or method is defined) of anything public
- Yes, you can add new methods and properties
- Default to private or internal. Don’t make anything public unless you are sure it needs to be public.
3. Liskov’s Substitution Principal
- Summary: Any class that implements an interface or a base class, will work just as well as another class that implement the same interface or base class. Classes that inherit from such, also should work just as well.
- Training Wheels:
- Implement interfaces / avoid base class inheritance
- Choose “Has a” over “Is a”
4. Interface Segregation Principal
- Summary: Keep your interfaces small and single responsibility.
- Training Wheels:
- See the S in Solid and the 10/100 Principle.
- A class with a max 100 lines should result in small interfaces. Might they need to be smaller, sure, but these are just training wheels.
- It is better to have a class implement more than one interface than to have a large interface. You can also have interfaces inherit other interfaces.
5. Dependency Inversion Principal
- Summary: A class doesn’t control it’s dependencies. A class depends only a interfaces, simple models
- Training Wheels:
- Use a Dependency Injection Container. For example, in C#, there DI container such as Autofac, Ninject, or the new one built into .Net.
- All dependencies are injected as interfaces using constructor injection
- i.e. Never use the ‘new’ keyword in a class that isn’t your one composition root or a DI module.
- All interface/concrete pairs are registered with the DI Container
- Almost never write a static. Statics are only for extremely simple utility methods, for example, in C#, very simple extension methods, such as string.Contains().
- If you encounter a static in existing code
- If it isn’t public, refactor it immediately to be non-static. If it is public, you can’t delete it, see the O in solid, so wrap it
6. Other Training Wheels
- Write Unit tests
- Unit Test are your first chance to prove your code is S.O.L.I.D.
- If you follow the above training wheels especially the S and D in solid, your code will be much easier to unit test.
- If you don’t write Unit Tests first (see TDD), at least write them simultaneously or immediately after each small piece of code.
- Use a mocking framework. For example, in C# use Moq.
- Unit Test are your first chance to prove your code is S.O.L.I.D.
Why use S.O.L.I.D. training wheels while coding?
Remember, these are training wheels. Just like training wheels on a bike helps you not crash, these S.O.L.I.D. training wheels will help you not crash your code (i.e. write unmaintainable code).
If you follow these training wheels, you will be amazed how:
- Your code is far easier to maintain.
- Your code is far easier to keep up-to-date.
- Your code naturally uses common design patterns even if you, the writer, haven’t learned about that design pattern yet.
- You code is testable.
- Other developers praise your code.